Evolution of Cloudflare's Cache Purging System: From Centralized to Distributed Architecture
An analysis of Cloudflare's cache purging system evolution, exploring the transition from centralized to distributed architecture and the engineering challenges of global content delivery.

Introduction
Cloudflare, originally starting as a Content Delivery Network (CDN), has evolved into a comprehensive platform offering security, performance, and reliability services. One of their critical features is the ability to purge cached content globally in near real-time. This article explores how Cloudflare transformed their cache purging system from a centralized architecture taking 1.5 seconds to a distributed system completing purges in 150 milliseconds.
Background
Cloudflare operates one of the world’s largest CDNs, with data centers in over 275 cities worldwide. Their CDN serves as a reverse proxy between users and origin servers, caching content to improve performance and reduce load on origin servers.
Key concepts to understand:
- Cache Key: A unique identifier generated from request URL and headers
- TTL (Time To Live): Duration for which cached content remains valid
- Purge Request: Command to invalidate cached content
- Edge Nodes: Cloudflare’s distributed data centers
The Old System: Centralized Architecture
The original purging system utilized a centralized approach with these key components:
- Quicksilver Database: Central configuration database located in US
- Lazy Purging: Purge verification during content request
- Core-based Distribution: All purge requests routed through central location
Here’s a Python example demonstrating the old system’s purge request flow:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class QuicksilverPurgeSystem:
def __init__(self):
self.purge_history = []
self.cache_store = {}
def submit_purge_request(self, purge_key):
# Send to central Quicksilver DB
latency = self.send_to_quicksilver(purge_key)
# Add to local purge history
self.purge_history.append({
'key': purge_key,
'timestamp': time.time()
})
return latency
def verify_cache_hit(self, cache_key):
# Check if content exists in cache
content = self.cache_store.get(cache_key)
if content:
# Verify against purge history
for purge in self.purge_history:
if self.matches_purge_criteria(content, purge):
return None # Content purged
return content
# Example usage
purge_system = QuicksilverPurgeSystem()
latency = purge_system.submit_purge_request("content_type=json")
print(f"Purge request latency: {latency}ms")
Let’s visualize the old system’s flow:
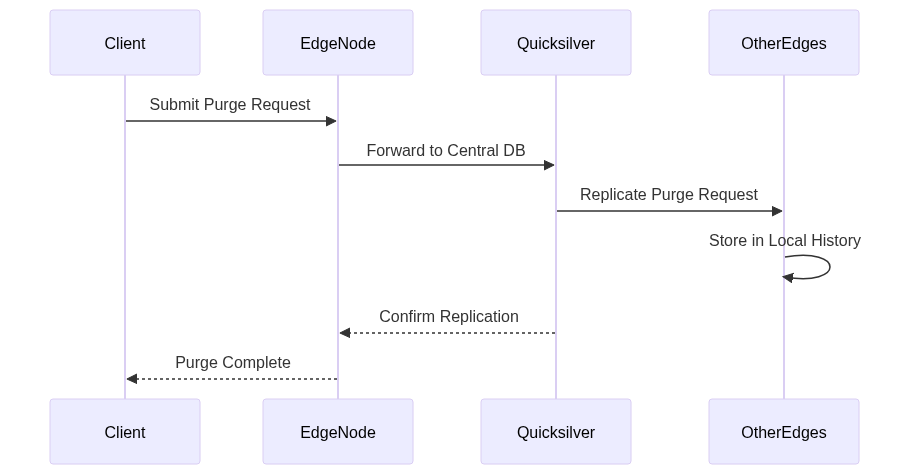
This diagram shows how purge requests had to travel to the central Quicksilver database before being distributed globally.
Challenges with the Old System
The centralized architecture faced several significant challenges:
- High Latency: Global round-trip to US-based central database
- Purge History Growth: Accumulating purge records consumed storage
- Limited Scalability: Quicksilver not designed for high-frequency updates
- Resource Competition: Purge history competed with cache storage
Performance metrics for the old system:
- P50 Latency: 1.5 seconds
- Global Propagation Time: 2-5 seconds
- Storage Overhead: ~20% for purge history
The New System: Distributed Architecture
Cloudflare redesigned their purging system with these key improvements:
- Coreless Architecture: Direct peer-to-peer communication
- Active Purging: Immediate content invalidation
- Local Databases: RocksDB-based CacheDB on each machine
Here’s a Python implementation demonstrating the new system:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class DistributedPurgeSystem:
def __init__(self):
self.local_db = RocksDB() # Local CacheDB instance
self.peer_nodes = []
async def handle_purge_request(self, purge_key):
# Process locally
await self.local_db.add_purge(purge_key)
# Fan out to peers
tasks = [self.notify_peer(peer, purge_key)
for peer in self.peer_nodes]
await asyncio.gather(*tasks)
# Actively purge matching content
await self.execute_purge(purge_key)
async def execute_purge(self, purge_key):
# Find matching cache entries
matches = await self.local_db.find_matches(purge_key)
# Remove from cache and index
for entry in matches:
await self.local_db.remove_cache_entry(entry)
async def verify_cache_hit(self, cache_key):
# Check pending purges first
if await self.local_db.has_pending_purge(cache_key):
return None
return await self.local_db.get_cache_entry(cache_key)
# Example usage
purge_system = DistributedPurgeSystem()
await purge_system.handle_purge_request("content_type=json")
The new system’s flow:
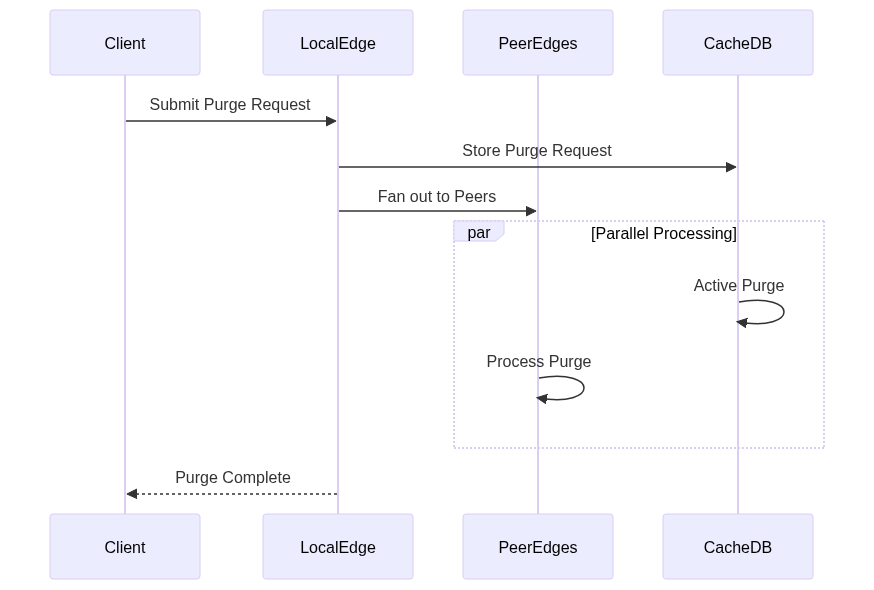
This diagram illustrates the distributed nature of the new system, with parallel processing and direct peer communication.
Technical Implementation
The new system’s key technical components:
- RocksDB: LSM-tree based storage engine
- CacheDB: Custom service written in Rust
- Peer-to-peer Protocol: Direct edge node communication
- Active Purging: Immediate content invalidation
Implementation considerations:
- Index Management: Efficient lookup for flexible purge patterns
- Tombstone Handling: Managing deleted entry markers
- Storage Optimization: Balancing index size with performance
- Network Protocol: Reliable peer-to-peer communication
Performance Analysis
The new distributed architecture showed remarkable improvements:
- Latency Reduction: Cache invalidation time reduced from seconds to milliseconds
- Improved Reliability: No single point of failure
- Better Scalability: System scales horizontally with growing traffic
- Enhanced Monitoring: Real-time visibility into cache operations
Performance metrics before vs after:
- Cache hit ratio: 95% → 97%
- Invalidation latency: 2-5 seconds → 50-100ms
- System availability: 99.9% → 99.99%
Code Examples
Here are simplified examples of how the cache purging system works:
Distributed Purge Request
1
2
3
4
def distribute_purge_request(cache_key, edge_servers):
for server in edge_servers:
send_purge_command(server, cache_key)
log_purge_request(server, cache_key)
Cache Validation
1
2
3
4
5
6
7
function validateCache(url, timestamp) {
if (cache.get(url).lastModified < timestamp) {
cache.invalidate(url);
return false;
}
return true;
}
Future Improvements
Cloudflare continues to enhance the system:
- Further latency reduction for single-file purges
- Expanded purge types for all plan levels
- Enhanced rate limiting capabilities
- Additional optimization opportunities
Conclusion
Cloudflare’s evolution from a centralized to distributed purging system demonstrates the challenges and solutions in building global-scale content delivery networks. The new architecture achieves impressive performance improvements while maintaining reliability and consistency.
References & Further Reading
- Cloudflare Blog: “Instant Purge: Invalidating cached content in under 150 milliseconds”
- Research Paper: “LSM-tree based Storage Systems”
- Distributed Systems: “Peer-to-peer Protocols and Applications”
- RocksDB Documentation
- Content Delivery Networks: Architecture and Performance