HTTP Message Size Handling: Content-Length and Chunked Transfer Encoding
A in-depth technical exploration of HTTP message body size handling mechanisms, examining Content-Length and Transfer-Encoding: chunked approaches with practical C implementations and real-world scenarios.

Understanding the Message Size Problem
When you send or receive data over HTTP, one fundamental question emerges: how does the receiver know when the message body ends? This seemingly simple question has profound implications for how we build web servers, APIs, and streaming applications.
HTTP operates over TCP, which provides a reliable byte stream but no inherent message boundaries. The protocol layer must establish these boundaries somehow. In the early days of HTTP/1.0, servers would simply close the connection after sending the response body. The connection closure itself signaled completion. This approach worked but had serious drawbacks. Every request required a new TCP connection, incurring the overhead of the three-way handshake each time.
HTTP/1.1 introduced persistent connections by default, allowing multiple request-response cycles over a single TCP connection. This improvement dramatically reduced latency and connection overhead, but it created a new challenge. Without connection closure as a signal, how do we delimit one message from the next? The answer lies in two mechanisms: Content-Length and Transfer-Encoding: chunked.
The Content-Length Approach
Content-Length represents the straightforward solution. Before sending the response headers, the server determines the exact size of the message body in bytes and includes this value as a header. The receiver reads the headers, extracts the Content-Length value, and then reads exactly that many bytes from the stream. Once those bytes are consumed, the message is complete, and the connection remains open for the next request.
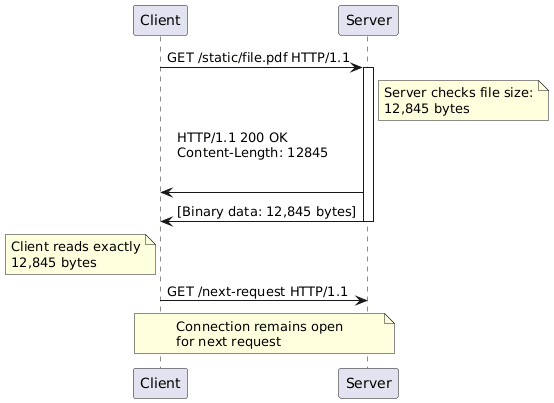
This mechanism works beautifully for static content. A web server serving a JPEG image knows the file size before sending any bytes. It performs a stat system call, gets the size, writes the headers including Content-Length, and streams the file contents. The client receives data until it has consumed exactly Content-Length bytes, then knows the response is complete.
Here’s a practical C implementation showing how a client handles Content-Length:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#define BUFFER_SIZE 4096
typedef struct {
long content_length;
int has_content_length;
} HttpHeaders;
HttpHeaders parse_headers(const char *headers) {
HttpHeaders result = {0, 0};
const char *cl_header = strstr(headers, "Content-Length:");
if (cl_header) {
cl_header += 15; // Skip "Content-Length:"
while (*cl_header == ' ') cl_header++;
result.content_length = atol(cl_header);
result.has_content_length = 1;
}
return result;
}
int read_with_content_length(int sockfd, long content_length) {
char buffer[BUFFER_SIZE];
long total_read = 0;
printf("Reading body with Content-Length: %ld bytes\n", content_length);
while (total_read < content_length) {
long to_read = content_length - total_read;
if (to_read > BUFFER_SIZE) to_read = BUFFER_SIZE;
ssize_t bytes_read = recv(sockfd, buffer, to_read, 0);
if (bytes_read <= 0) {
fprintf(stderr, "Connection closed prematurely\n");
return -1;
}
total_read += bytes_read;
printf("Read %zd bytes, total: %ld/%ld\n",
bytes_read, total_read, content_length);
}
printf("Successfully read complete body\n");
return 0;
}
int main() {
// Simulated response from server
const char *response =
"HTTP/1.1 200 OK\r\n"
"Content-Type: text/plain\r\n"
"Content-Length: 27\r\n"
"\r\n"
"{\"key\": \"value\", \"id\": 123}";
// Find end of headers
const char *body_start = strstr(response, "\r\n\r\n");
if (!body_start) {
fprintf(stderr, "Invalid HTTP response\n");
return 1;
}
body_start += 4; // Skip the \r\n\r\n
// Parse headers
size_t header_len = body_start - response;
char *headers = strndup(response, header_len);
HttpHeaders parsed = parse_headers(headers);
if (parsed.has_content_length) {
printf("Content-Length found: %ld\n", parsed.content_length);
printf("Body content: %.*s\n",
(int)parsed.content_length, body_start);
}
free(headers);
return 0;
}
Compile and run this code:
1
2
gcc -o http_content_length http_content_length.c -Wall
./http_content_length
The output demonstrates how a client extracts the Content-Length value and reads exactly that many bytes from the response body. The critical insight is that once you know the size upfront, parsing becomes deterministic. You read N bytes and you’re done.
When Size is Unknown: Chunked Transfer Encoding
Many real-world scenarios cannot provide Content-Length upfront. Consider a web server generating HTML dynamically from database queries. The server could buffer the entire response in memory, count the bytes, and then send Content-Length followed by the body. But this approach wastes memory and introduces latency. The first byte cannot be sent until the last byte is generated.
Streaming video presents an even more extreme case. A live stream has no predetermined end. The content is being created in real time. Content-Length is meaningless here.
Transfer-Encoding: chunked solves this by breaking the body into chunks, each prefixed with its size. The protocol is straightforward. Each chunk consists of:
- The chunk size in hexadecimal, followed by CRLF
- The chunk data itself
- Another CRLF
- Repeat until a zero-sized chunk signals completion
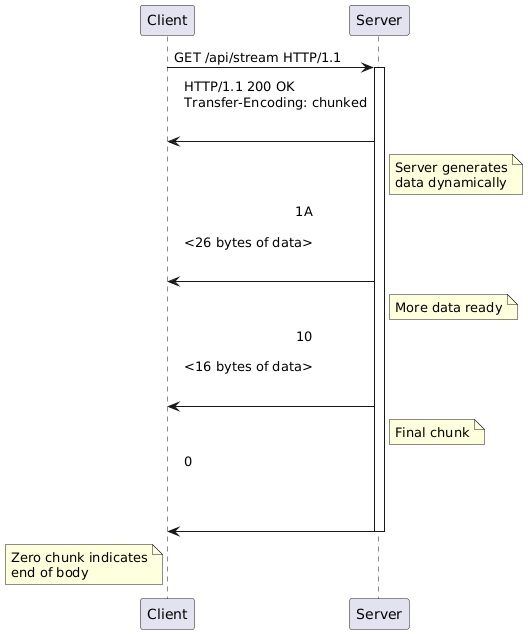
The beauty of chunked encoding lies in its incremental nature. The server can generate and send data as it becomes available. The client processes chunks as they arrive, never needing to know the total size. When the server finishes, it sends a zero-length chunk, cleanly terminating the body without closing the connection.
Here’s a C implementation of a chunked transfer decoder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#define MAX_CHUNK_SIZE 8192
typedef struct {
char *data;
size_t size;
size_t capacity;
} Buffer;
Buffer *buffer_create() {
Buffer *buf = malloc(sizeof(Buffer));
buf->capacity = 1024;
buf->size = 0;
buf->data = malloc(buf->capacity);
return buf;
}
void buffer_append(Buffer *buf, const char *data, size_t len) {
while (buf->size + len > buf->capacity) {
buf->capacity *= 2;
buf->data = realloc(buf->data, buf->capacity);
}
memcpy(buf->data + buf->size, data, len);
buf->size += len;
}
long parse_hex_size(const char *hex_str) {
return strtol(hex_str, NULL, 16);
}
int read_chunked_body(const char *chunked_data, Buffer *output) {
const char *ptr = chunked_data;
while (1) {
// Read chunk size line
char size_line[32];
int i = 0;
while (*ptr != '\r' && i < 31) {
size_line[i++] = *ptr++;
}
size_line[i] = '\0';
// Skip \r\n
if (*ptr == '\r') ptr++;
if (*ptr == '\n') ptr++;
long chunk_size = parse_hex_size(size_line);
printf("Chunk size: 0x%s = %ld bytes\n", size_line, chunk_size);
if (chunk_size == 0) {
printf("Final chunk received, body complete\n");
break;
}
// Read chunk data
buffer_append(output, ptr, chunk_size);
ptr += chunk_size;
// Skip trailing \r\n
if (*ptr == '\r') ptr++;
if (*ptr == '\n') ptr++;
}
return 0;
}
int main() {
// Simulated chunked response
const char *chunked_response =
"1A\r\n"
"This is the first chunk!\r\n"
"\r\n"
"10\r\n"
"Second chunk...\r\n"
"\r\n"
"D\r\n"
"Final piece.\r\n"
"\r\n"
"0\r\n"
"\r\n";
Buffer *body = buffer_create();
printf("Decoding chunked transfer encoding:\n\n");
read_chunked_body(chunked_response, body);
printf("\nReconstructed body (%zu bytes):\n", body->size);
printf("%.*s\n", (int)body->size, body->data);
free(body->data);
free(body);
return 0;
}
Compile and test:
1
2
gcc -o http_chunked http_chunked.c -Wall
./http_chunked
This implementation demonstrates the parsing logic for chunked encoding. Notice how the decoder reads each chunk size, extracts that many bytes, and continues until it encounters a zero-sized chunk. The complete body is reconstructed incrementally without ever knowing its total size upfront.
Practical Implications and Trade-offs
Choosing between Content-Length and chunked encoding involves understanding your data characteristics and performance requirements.
Content-Length excels when serving static files or pre-computed responses. Web servers like Nginx use sendfile system calls to efficiently stream files directly from disk to network, leveraging zero-copy mechanisms. The Content-Length header enables TCP-level optimizations, as the kernel knows exactly how much data to send. Clients benefit too, displaying accurate progress bars during downloads because they know the total size upfront.
Chunked encoding becomes essential for dynamic content generation. Application servers processing API requests often compute responses on the fly, querying databases and assembling JSON incrementally. Buffering the entire response before sending would increase both latency and memory consumption. Streaming chunks as data becomes available reduces time to first byte and enables better resource utilization.
Real-time applications like server-sent events or streaming analytics absolutely require chunked encoding. The data has no predetermined end, making Content-Length impossible. Each event or data point becomes a chunk, pushed to clients as it occurs.
Modern load balancers and reverse proxies handle these mechanisms automatically. When you deploy an application behind Nginx or HAProxy, these tools often rewrite responses, potentially converting between Content-Length and chunked encoding based on buffering decisions and downstream connection characteristics.
Implementation Considerations
When building HTTP clients or servers, you must handle both mechanisms correctly. A robust implementation checks for Content-Length first. If present and valid, it reads exactly that many bytes. If absent, it looks for Transfer-Encoding: chunked and invokes the chunked decoder. HTTP/1.1 requires one of these two methods for any response with a body, unless the connection is being closed.
Error handling matters significantly. What if Content-Length claims 1000 bytes but the connection closes after 500? Your code must detect this truncation and handle it gracefully, perhaps retrying the request. With chunked encoding, what if you receive malformed chunk sizes or unexpected data? Proper validation prevents hanging reads or buffer overflows.
Security considerations include protecting against attacks where malicious Content-Length values attempt to cause integer overflows or excessive memory allocation. Similarly, chunked encoding parsers must guard against excessively large chunk declarations that could exhaust memory.
You can test these implementations using netcat or telnet. Create a simple HTTP response and pipe it to your parsing code:
1
2
3
4
5
6
7
8
9
10
11
# Create a test response with Content-Length
cat > test_response.txt << 'EOF'
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 27
{"key": "value", "id": 123}
EOF
# Test with your client
cat test_response.txt | ./http_content_length
For chunked responses, construct the encoded format manually and verify your decoder handles it correctly.
Try It Yourself
Extend your understanding by implementing these enhancements to the provided code examples.
Exercise 1: Multi-Request Pipeline Parser
Modify the Content-Length example to handle multiple HTTP responses in sequence over a single persistent connection. After reading one complete response, the parser should immediately begin reading the next response headers. This simulates how HTTP/1.1 persistent connections work in practice.
Add a function that takes a buffer containing multiple concatenated HTTP responses and successfully parses each one, handling varying Content-Length values. Test with at least three different responses in sequence.
Exercise 2: Chunked Encoder
Create the inverse of the chunked decoder, a function that takes arbitrary data and encodes it into chunked transfer format. Your encoder should split input data into configurable chunk sizes and generate proper hexadecimal size prefixes with correct CRLF delimiters.
Implement a parameter to control maximum chunk size, then test by encoding various inputs and verifying your decoder from the original example can reconstruct them perfectly. This exercise demonstrates the complete encode-decode cycle.
Exercise 3: Hybrid Protocol Handler
Build a unified HTTP body reader that automatically detects whether a response uses Content-Length or Transfer-Encoding and processes it accordingly. The function should examine the headers, determine the framing mechanism, and invoke the appropriate reading logic.
Add support for handling the edge case where neither header is present and the response body continues until connection closure, as was common in HTTP/1.0. This creates a complete, production-ready HTTP body parser.
Conclusion
HTTP message size handling represents a elegant solution to the fundamental problem of framing data in a streaming protocol. Content-Length provides efficiency and simplicity for known-size content, while chunked transfer encoding enables streaming and dynamic generation scenarios that are essential for modern web applications.
Understanding these mechanisms at the protocol level rather than abstracting them away behind libraries gives you the insight needed to debug network issues, optimize application performance, and make informed architectural decisions. When you encounter slow API responses or streaming failures, you’ll know to examine whether the right framing mechanism is being used and whether it’s being handled correctly.
The implementations provided here offer a foundation for building robust HTTP clients and servers. Whether you’re working with embedded systems that need lightweight HTTP handling or debugging production issues with transfer encoding, having a solid grasp of these core protocols proves invaluable throughout your career in systems programming and distributed systems architecture.