Technical Autopsy of the AWS US-EAST-1 Internal DNS Resolution Failure and DynamoDB Disruption
A comprehensive technical analysis of the October 2025 AWS US-EAST-1 outage caused by a DNS race condition in DynamoDB's automation system that cascaded across the entire regional control plane.

On October 19, 2025 at 23:48 PDT (October 20 06:48 UTC) a latent race condition in DynamoDB’s automated DNS management system caused the authoritative DNS records for the DynamoDB regional endpoint (dynamodb.us-east-1.amazonaws.com) and several related internal endpoints to be wiped to an empty A/AAAA record set. The resulting NOERROR responses with an empty answer section made the service completely unresolvable for any client that had not already cached a valid record set. Because virtually every AWS control-plane service in US-EAST-1 depends on DynamoDB for metadata, configuration, feature flags, or service discovery, the loss of endpoint resolution immediately blocked new connections to DynamoDB from both customer and internal traffic. Existing connections continued to function until they drained or were restarted, but no new control-plane or data-plane operations that required DynamoDB could proceed.
Executive Summary
The primary DynamoDB resolution failure lasted from 23:48 PDT October 19 until 02:40 PDT October 20 (3 hours 52 minutes). Secondary effects on EC2 instance launches, Network Load Balancer health checking, Lambda scaling, and dozens of other services extended major customer impact until approximately 14:20 PDT (21:20 UTC) October 20, for a total event duration of ≈14 hours 32 minutes. Peak unavailability across the affected services exceeded 90 % for several hours in the morning of October 20 when NLB health-check storms and EC2 droplet-lease backlogs compounded.
One-sentence root cause: A race condition between two independent DNS Enactor instances, combined with a stale “newer-plan” check and an aggressive plan-cleanup process, allowed an old plan to overwrite a newer plan and then be immediately deleted, resulting in an empty authoritative answer section for the regional DynamoDB endpoint.
This was fundamentally an internal DNS publication failure that manifested first as a DynamoDB outage because internal control-plane clients use the same regional endpoints (or aliases that resolve through the same records) via HyperResolver and the internal anycast VIP fleet. Once DynamoDB became unreachable, the keystone role of US-EAST-1 DynamoDB partitions caused a rapid cascade across the entire regional control plane and many “global” services that secretly pin metadata to US-EAST-1 tables.
Background: Relevant US-EAST-1 and AWS Control-Plane Architecture in 2025
US-EAST-1 in 2025 remains the largest AWS region with 8 publicly acknowledged Availability Zones and hundreds of thousands of physical hosts. It hosts. The region contains the primary metadata partition for dozens of global services and the majority of control-plane DynamoDB tables.
AWS deliberately separates control plane (API, authentication, configuration, service discovery) from data plane (customer workload traffic). Control-plane traffic is routed through a dedicated internal network backbone and resolves service endpoints through an entirely separate internal DNS infrastructure that is topologically and operationally separate from public Route 53. The internal DNS system consists of:
- HyperResolver resolver fleets (anycast 169.254.169.253 + regional VIPs)
- Multiple caching layers (local instance cache, VPC Resolver cache, regional cache)
- Authoritative backend fleets running on Hyperplane (internal L4 LB service)
- Authoritative zones for *.amazonaws.com and *.internal.amazonaws.com served from multiple geographically distributed authoritative clusters
Service endpoints are published as CNAME chains that ultimately resolve to Hyperplane anycast VIPs that front the actual service fleet. DynamoDB is a keystone service stores control-plane metadata for IAM, STS, Service Catalog, CloudFormation, Lambda@Edge configuration, API Gateway custom domains, Lambda concurrency metadata, ECS/EKS task metadata, and many others. Even “global” services such as IAM and STS keep their primary durable state in US-EAST-1 DynamoDB tables with cross-region replication for read replicas. Losing write (or even read) access to these tables blocks authentication, configuration changes, and new resource creation across the entire AWS footprint, not just US-EAST-1.
Hyperplane, the internal L4 load balancer, depends on internal DNS for target registration and health-check destination resolution. When the DynamoDB endpoint record set became empty, Hyperplane instances could not register new targets or refresh health because the registration path itself required DynamoDB writes.
Detailed Timeline of the Outage
All times shown in PDT (Pacific Daylight Time):
Phase 1: Initial Failure and Detection (October 19 - Early October 20)
| Time | Event |
|---|---|
| 23:48 October 19 | First elevated DynamoDB API errors observed; authoritative DNS records for dynamodb.us-east-1.amazonaws.com become empty |
| 23:51 | Internal monitoring detects DNS resolution failures; Lambda, ECS/Fargate, STS begin failing |
| 00:38 October 20 | Engineers identify empty authoritative record set |
| 01:15 | Temporary manual overrides applied for critical internal endpoints; some internal tooling recovers |
| 02:25 | Full manual restoration of correct record set; cached records begin expiring |
| 02:40 | DynamoDB API error rate returns to normal as client caches expire |
Phase 2: Secondary Cascade and Recovery (October 20)
| Time | Event |
|---|---|
| 04:14 | DWFM (DropletWorkflow Manager) congestive collapse identified; throttling and selective restarts begin |
| 05:30 | NLB health-check storm begins as backlog of new EC2 instances flood health subsystems |
| 06:52 | NLB automatic AZ failover triggers detected at scale |
| 09:36 | Automatic health-check failover disabled globally for NLB to stop capacity oscillation |
| 10:36 | Network Manager backlog cleared; new instance connectivity restored |
| 13:50 | EC2 launch throttling fully relaxed |
| 14:09 | NLB health-check failover re-enabled |
| 14:20 | Final customer-facing impact cleared |
Total Duration: ~14 hours 32 minutes (23:48 PDT October 19 → 14:20 PDT October 20)
Root Cause Analysis
The trigger was a latent race condition in DynamoDB’s DNS automation that had existed undetected for years.
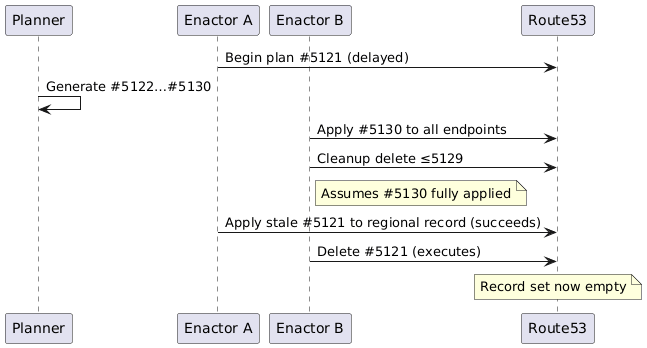
DynamoDB maintains hundreds of thousands of A/AAAA records pointing to Hyperplane VIPs fronting Network Load Balancers. A DNS Planner generates new “plans” (ordered list of IPs + weights) every few minutes. Three independent DNS Enactor instances (one per AZ for resiliency) race to apply the latest plan via Route53 transactions (internal authoritative zones are also updated via the same API surface).
The failing sequence (simplified):
- Enactor A picks plan #5121, begins applying, but experiences unusual delay before reaching the regional endpoint record. 2 Planner continues generating #5122, #5123 … #5130. 3 Enactor B picks #5130, applies it rapidly to all endpoints including the regional one. 4 Enactor B triggers cleanup, deleting all plans ≤ #5129. 5 Delayed Enactor A finally applies stale #5121 to the regional endpoint (stale “is-newer” check passed earlier). 6 Cleanup from Enactor B deletes #5121 → record set becomes empty.
The transaction that applied the stale plan succeeded because the “newer-plan” check was performed once at the beginning, not per-record. No locking or per-record versioning existed. Critically, the cleanup logic assumed any plan that old must be safe to delete because the applying Enactor “should have” completed.
Canaries did not catch this because the canary validated the plan content, not the transaction semantics under delay. Rollback mechanisms required the same automation that was now broken (no active plan existed to repair itself).
The failure mode was NOERROR with empty answer section (not NXDOMAIN). Clients treat this as “service intentionally has no IPs” and immediately fail rather than retry or fallback.
Internal DNS Resolution Failure

In normal operation an internal client (e.g., Lambda worker, EC2 host agent, control-plane service) issues a DNS query to the well-known anycast address 169.254.169.253. HyperResolver performs iterative resolution:
- Check local cache (typically 60–300 s TTL for control-plane records) 2 If miss → forward to regional HyperResolver cache fleet (anycast VIP) 3 Regional cache checks its cache 4 If miss → iterative query to internal authoritative anycast VIP 5 Authoritative returns CNAME chain → Hyperplane VIP records → A/AAAA set 6 Return to client with TTL
During the incident the authoritative backend returned NOERROR + empty answer section + SOA. Packet capture:
1
2
3
;; ANSWER SECTION:
dynamodb.us-east-1.amazonaws.com. 60 IN CNAME ddb.us-east-1.prod.internal.
ddb.us-east-1.prod.internal. 60 IN NOERROR (empty)
Clients receiving this immediately stop resolution (no IPs to connect to). No retry storm against authoritative because the response is authoritative and valid. Caches correctly stored the empty answer. With 60 s TTL the poison propagated region-wide within ≈2 minutes.
Why caching did not help: control-plane records deliberately use short TTLs (30–60 s) to allow rapid fleet churn and failure isolation. Once poisoned, every cache layer faithfully cached the empty answer until TTL expiry or manual invalidation.
Thundering herd on recovery: when records were restored at 02:25 PDT, millions of control-plane clients simultaneously retried cached-expired queries → massive spike against authoritative fleet. Authoritative backends are designed for this, but DWFM and Network Manager subsystems were already backlogged → secondary collapse.
Comparison with public Route 53: public Route 53 zones were unaffected because DynamoDB automation maintains separate public and internal record sets. Public customers using only non-US-EAST-1 tables were fine; internal services and customers with US-EAST-1 tables or replication lag were not.
Why DynamoDB Became Unreachable and the Cascade Began
DynamoDB is the primary durable store for control-plane metadata in US-EAST-1 even in 2025. Examples:
- IAM policies, STS token metadata, Service Catalog portfolios
- Lambda concurrency limits, version metadata, alias routing tables
- API Gateway custom domain mappings
- CloudFormation state machine progress
- ECS/EKS task definitions and desired counts
When the endpoint returned empty records, every attempt to read or write this metadata failed with connection failure. Existing connections drained, but any operation requiring a new connection (most control-plane actions) blocked.
Feedback loops:
- Failed DynamoDB calls → client retries (exponential backoff + jitter insufficient)
- Retries → increased load on HyperResolver and surviving paths
- DWFM lease renewals fail → droplet leases expire → droplets become ineligible for new launches
- New instance launches return “insufficient capacity” even when capacity exists
- Network Manager backlog → newly launched instances no network → NLB health checks fail → panic removal → AZ failover → capacity oscillation
TLS/TCP interaction: clients receive IP list of zero → TLS SNI handshake fails at TCP connection stage (no target IP). No TLS errors appear because TCP cannot even start.
Blast Radius and Customer Impact
Major impaired services (partial list):
- Console sign-in (IAM/IAM Identity Center)
- STS token issuance (global impact)
- Lambda new invocations/scaling
- ECS/EKS/Fargate task launches
- EC2 new instance launches
- NLB connection errors
- API Gateway, CloudFormation, Service Catalog, Outposts
Notable external outages: Roblox (could not scale), Epic Games (Fortnite login failed), Coinbase, Twitch (stream ingest failed), many SaaS providers using Lambda@Edge.
Multi-region active/active customers with global tables survived with replication lag; single-region or “global” services pinning to US-EAST-1 failed hard.
Why This Class of Failure Remains Hard to Eliminate in 2025
DynamoDB remains the keystone data store; full multi-region active control plane not yet complete in 2025. Empty answer is a valid DNS response; hard to synthetically validate “should have IPs”. Short TTLs necessary for rapid recovery trade off against cache poisoning resilience.
Similar to Dec 7 2021 congestion event but worse because empty answer requires no capacity to poison caches.
Post-Mortem Actions and Mitigations AWS Has Implemented Since October 2025
AWS disabled the Planner/Enactor automation worldwide and fixed the race condition (per-record versioning + lock). Added synthetic transactions that validate non-empty answer before commit. Implemented velocity limits on NLB AZ failover. Improved DWFM queue back-pressure detection and auto-throttling. Building multi-region active control-plane metadata for critical services (in progress as of November 2025). These mitigations materially reduce probability of recurrence to near-zero for this specific path.
Lessons for Cloud Architects and Operators in 2025 and Beyond
- Assume US-EAST-1 control-plane loss is possible; design metadata multi-region active or eventual-consistency tolerant
- Use global tables with client-side read-your-writes from non-US-EAST-1 replicas
- Implement client-side circuit breakers on DNS empty-answer (treat as transient error, exponential backoff)
- Chaos inject empty DNS answers in pre-prod
- Monitor for NOERROR + empty answer as distinct metric

Conclusion
With the fixes deployed, AWS control-plane architecture is now materially more resilient to DNS publication bugs of this class, though keystone dependency on US-EAST-1 DynamoDB remains the dominant single point of failure for the global control plane.