Why does Kafka use long polling instead of websockets?
An analysis of Kafka's design decisions, exploring why it uses long polling over WebSockets for real-time communication and the trade-offs involved.

Real-time communication over the internet involves more than just sending data quickly. The choice between different communication patterns—long polling, WebSockets, or pull-based systems like Kafka—depends on specific requirements like scalability, latency, and state management. Let’s examine why these patterns exist and when each makes sense.
Long Polling vs. WebSockets: Understanding the Fundamentals
Both long polling and WebSockets enable real-time communication between clients and servers without constant polling. They’re built on TCP, the reliable, connection-oriented protocol that ensures ordered packet delivery. However, they approach the challenge of real-time communication quite differently.
Long Polling: The Patient Waiter
Long polling resembles a client sitting at a restaurant, asking the server, “Got any new food yet?” Instead of immediately saying “no” and walking away, the server holds the request open, waiting until something new becomes available.
Here’s how long polling works:
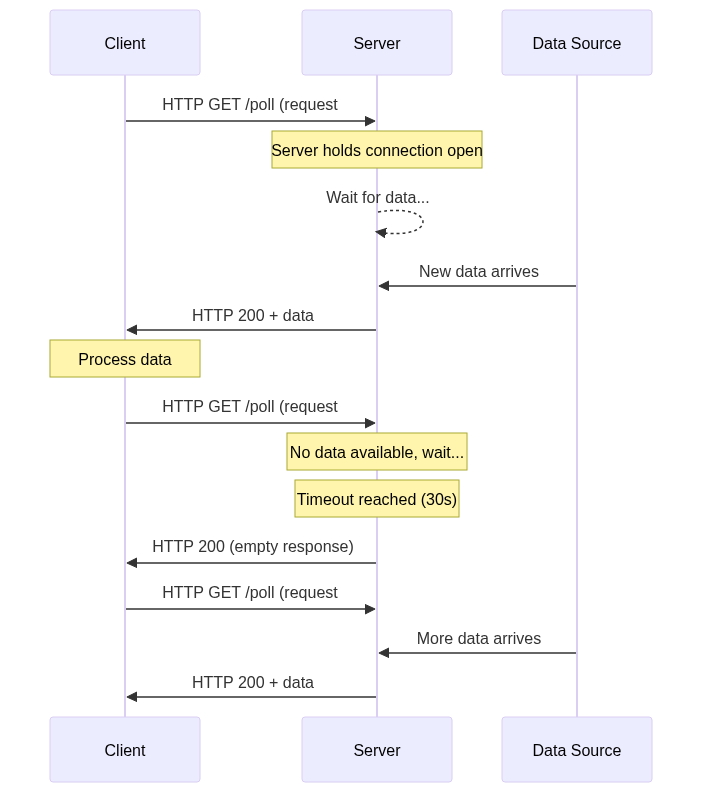
The long polling process:
- Client Request: The client sends an HTTP request to the server (typically GET)
- Server Wait: If no new data exists, the server keeps the TCP connection open instead of responding immediately
- Data Delivery: When new data arrives, the server sends the response and closes the connection
- Cycle Restart: The client immediately sends another request to continue the cycle
- Timeout Handling: If no data appears after a set time (usually 30 seconds), the server sends an empty response
Advantages:
- Works with existing HTTP infrastructure
- Simple implementation
- Universal support across browsers and servers
- No special server configuration required
Disadvantages:
- Each poll creates a new HTTP request with full headers
- Not truly bidirectional—client always initiates
- Potential delays if data arrives just after a timeout
- Higher protocol overhead
WebSockets: The Two-Way Radio
WebSockets establish a persistent, bidirectional connection between client and server. They begin with HTTP but quickly transition to a more efficient protocol.
WebSocket Connection Flow:
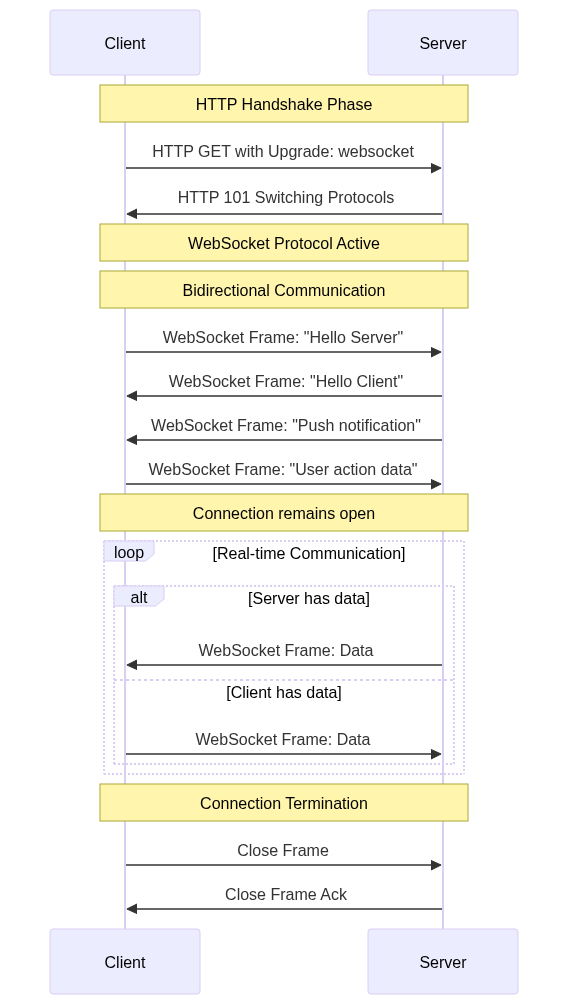
1
2
3
4
5
6
7
8
9
10
11
// WebSocket client example
const ws = new WebSocket('ws://localhost:8080');
ws.onopen = function() {
console.log('Connected');
ws.send('Hello Server');
};
ws.onmessage = function(event) {
console.log('Received:', event.data);
};
Advantages:
- True bidirectional communication
- Low latency
- Minimal overhead after handshake
- Single connection handles multiple messages
Disadvantages:
- Requires WebSocket protocol support
- Stateful connections complicate scaling
- More complex infrastructure requirements
TCP Connection Management
Both approaches maintain long-lived TCP connections with kernels waiting for interrupts. The key difference lies in the protocol layer:
Protocol Comparison:
- Long Polling: Uses HTTP with full request/response overhead
- WebSockets: Uses lightweight framing protocol after initial handshake
In both cases, the kernel waits for events—data arrival, timeouts, or errors—but WebSockets prove more efficient for frequent, small updates due to reduced protocol overhead.
Kafka’s Pull-Based Architecture
Kafka takes a different approach entirely. Instead of pushing data to consumers, it implements a pull-based system where consumers actively request data using consumer.poll(). This design choice stems from Kafka’s focus on scalability and flexibility in distributed messaging systems.
Why Pull Instead of Push?
Kafka Architecture Overview:
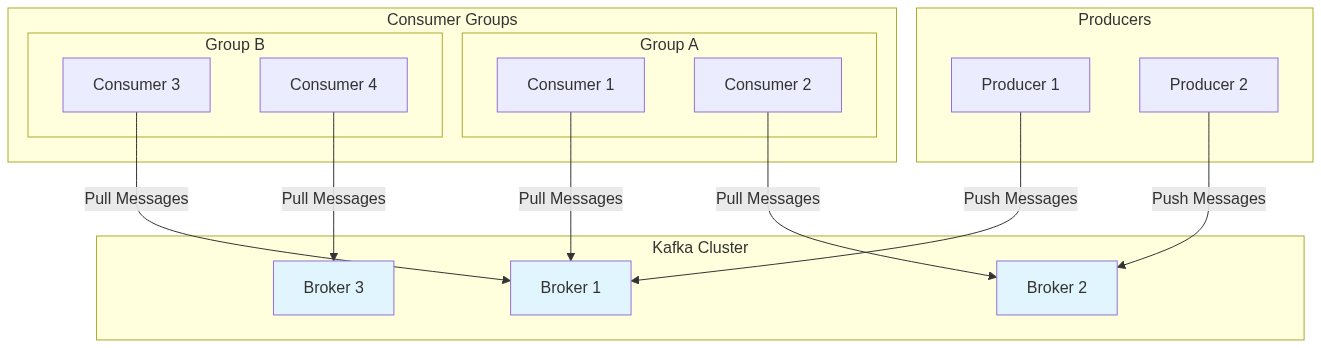
Kafka Consumer Pull Flow:
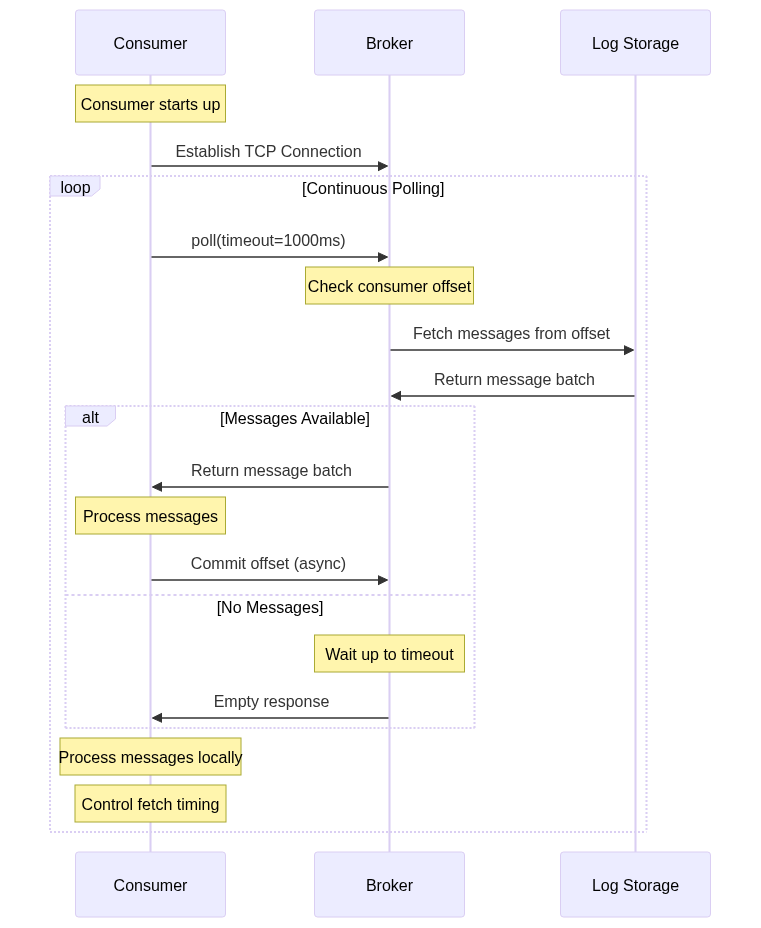
Kafka handles massive data streams—logs, events, metrics—flowing at extremely high rates. The pull-based model offers several advantages:
Consumer Control: Consumers decide when and how much data to fetch. One consumer might poll every second for small batches, while another waits daily to grab gigabytes for batch processing.
1
2
3
4
5
6
// Kafka consumer example
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
// Process record
System.out.println("Offset: " + record.offset() + ", Value: " + record.value());
}
Stateless Brokers: Push-based systems require brokers to track each consumer’s state—current position, processing capacity, readiness for more data. With thousands or millions of consumers, this becomes a memory and coordination nightmare. Pull-based systems offload this responsibility to consumers, which track their own offsets.
State Management Comparison:
Independent Scaling: Brokers serve whoever requests data without managing individual consumer needs. Consumers can scale independently by adding instances to handle load, and brokers remain unaware of these changes.
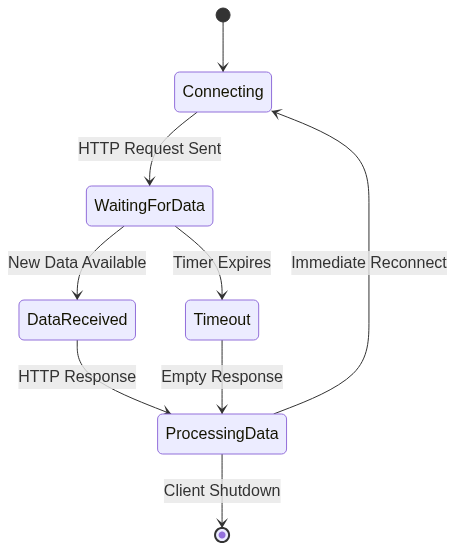
Long-Lived Connections in Kafka
Kafka clients maintain persistent TCP connections to brokers, similar to WebSockets or long polling. This avoids the overhead of repeatedly establishing connections, which would overwhelm brokers with handshakes and teardowns.
Kafka Connection Lifecycle:
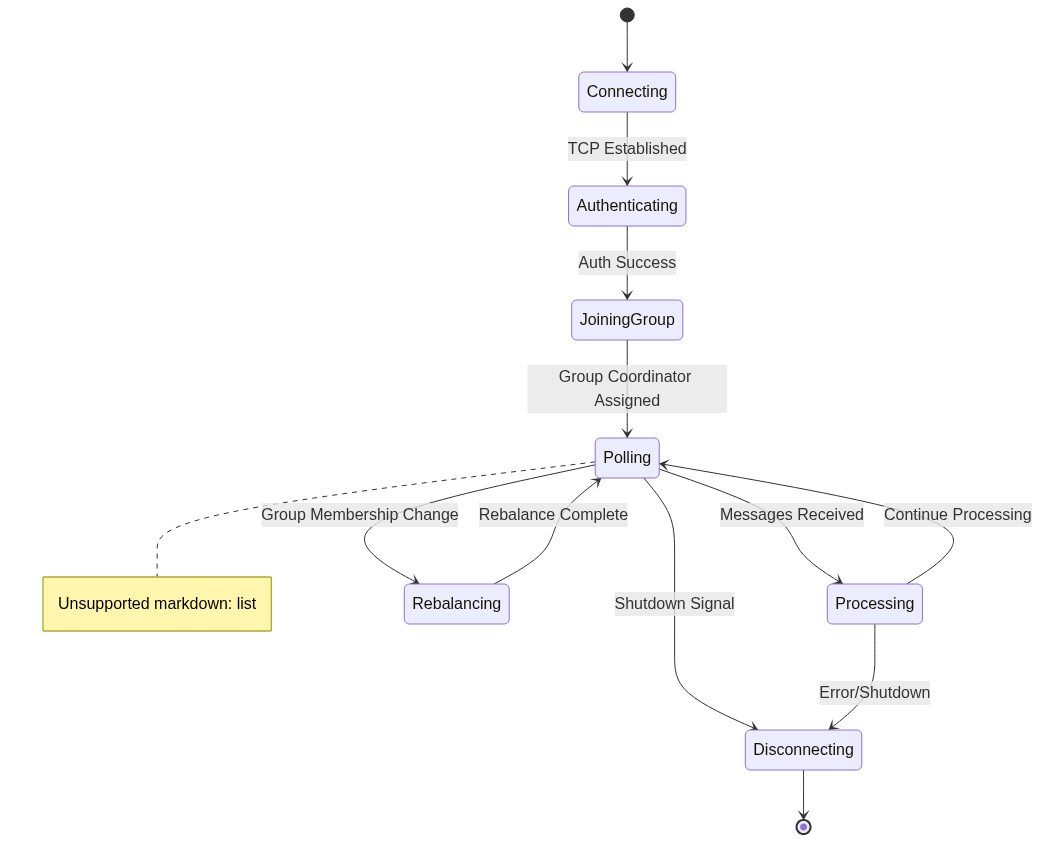
When a consumer calls poll(), it sends a request over the existing TCP connection, asking for new messages since its last offset. The broker responds with available data (up to configured limits), and the connection remains open for subsequent polls.
1
2
3
4
5
// Kafka consumer configuration for connection management
Properties props = new Properties();
props.put("connections.max.idle.ms", 540000); // Keep connections alive
props.put("session.timeout.ms", 30000); // Session timeout
props.put("fetch.max.wait.ms", 500); // Max wait for data
This differs from long polling in that poll() returns immediately (or after a short timeout) with whatever data is available. If nothing exists, the consumer simply polls again rather than waiting for new data to arrive.
Why Not WebSockets for Kafka?
WebSockets could theoretically work for Kafka, but they’d be a poor fit. Let’s compare the approaches:
Push vs Pull Architecture Comparison:
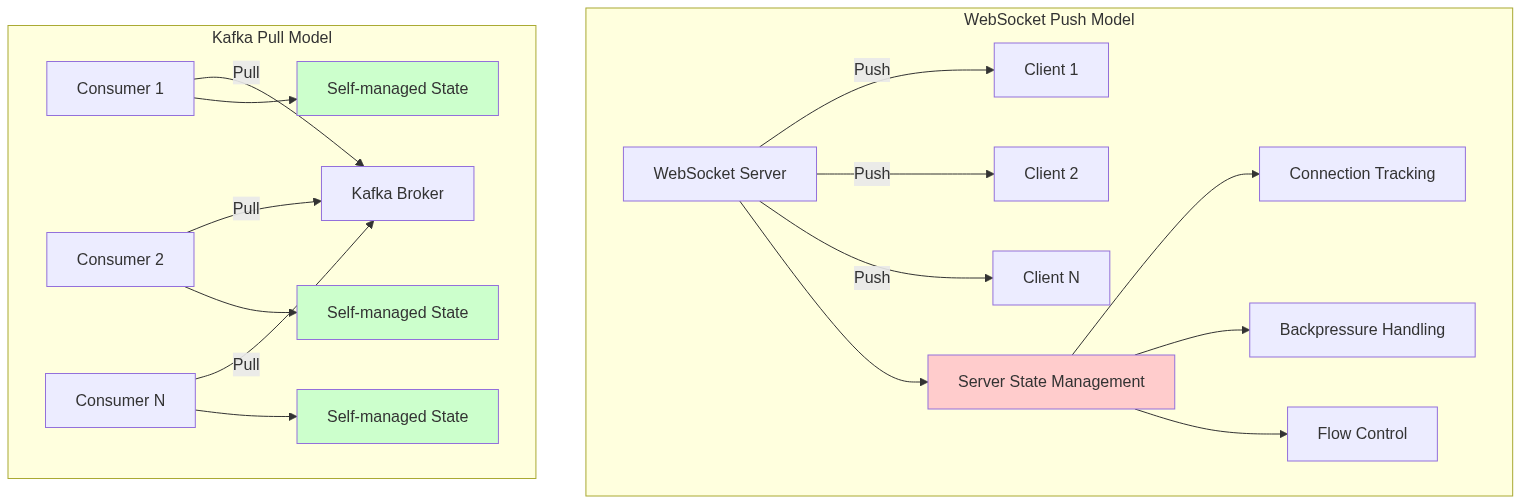
WebSockets excel at low-latency, bidirectional applications where both sides send small, frequent updates. Kafka deals with high-throughput, ordered message streams, often handling millions of messages per second.
A push-based WebSocket system would require brokers to:
- Manage active connections for every consumer
- Track individual consumer state
- Handle varying consumer processing speeds
- Manage failures and network issues
- Decide when to send data
Pull-based poll() keeps the system simple: consumers request data when ready, and brokers simply serve requests.
Performance Comparison
Different communication patterns excel in different scenarios:
| Pattern | Use Case | Latency | Throughput | Complexity | Connection Overhead |
|---|---|---|---|---|---|
| Long Polling | Real-time web apps | Medium | Low-Medium | Low | High (HTTP headers) |
| WebSockets | Interactive applications | Low | Medium | Medium | Low (after handshake) |
| Kafka Pull | High-throughput streaming | Medium | Very High | High | Low (persistent TCP) |
Long Polling Performance
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Long polling client example
import requests
import time
def long_poll():
while True:
try:
response = requests.get('http://api.example.com/poll', timeout=30)
if response.status_code == 200:
data = response.json()
if data:
process_data(data)
except requests.Timeout:
# Timeout reached, poll again
continue
except Exception as e:
time.sleep(5) # Wait before retrying
WebSocket Performance
1
2
3
4
5
6
7
8
9
10
11
12
// WebSocket with message batching
const ws = new WebSocket('ws://localhost:8080');
const messageQueue = [];
ws.onmessage = function(event) {
messageQueue.push(JSON.parse(event.data));
// Process messages in batches
if (messageQueue.length >= 100) {
processBatch(messageQueue.splice(0, 100));
}
};
Kafka Performance Optimization
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// Optimized Kafka consumer
Properties props = new Properties();
props.put("fetch.min.bytes", 1024); // Wait for minimum data
props.put("fetch.max.wait.ms", 500); // Maximum wait time
props.put("max.poll.records", 1000); // Records per poll
props.put("enable.auto.commit", false); // Manual offset management
// Batch processing
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
// Process entire partition batch
processBatch(partitionRecords);
// Commit offset after successful processing
consumer.commitSync(Collections.singletonMap(partition,
new OffsetAndMetadata(partitionRecords.get(partitionRecords.size() - 1).offset() + 1)));
}
}
Use Case Analysis
When to Use Long Polling
- Web applications requiring real-time updates
- Simple notification systems
- Scenarios with existing HTTP infrastructure
- Applications with infrequent updates
Example: A web dashboard displaying system status that updates every few seconds.
When to Use WebSockets
- Interactive applications requiring low latency
- Gaming platforms
- Live chat applications
- Real-time collaboration tools
Example: A collaborative document editor where multiple users edit simultaneously.
When to Use Kafka’s Pull Model
- High-throughput data streaming
- Event sourcing systems
- Log aggregation
- Systems requiring guaranteed message delivery and ordering
Example: Processing millions of user activity events for analytics and recommendations.
Implementation Considerations
Connection Management
All three patterns require careful connection management:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Connection pooling for long polling
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
Error Handling and Resilience
1
2
3
4
5
6
7
8
9
10
11
12
13
// Kafka consumer with error handling
while (true) {
try {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
processRecords(records);
} catch (WakeupException e) {
// Shutdown signal
break;
} catch (Exception e) {
logger.error("Error processing records", e);
// Implement retry logic or dead letter queue
}
}
Conclusion
The choice between long polling, WebSockets, and pull-based systems like Kafka depends on specific requirements:
Summary Comparison:
quadrantChart
title Communication Pattern Selection
x-axis Low Complexity --> High Complexity
y-axis Low Throughput --> High Throughput
quadrant-1 High Throughput, High Complexity
quadrant-2 High Throughput, Low Complexity
quadrant-3 Low Throughput, Low Complexity
quadrant-4 Low Throughput, High Complexity
Long Polling: [0.2, 0.3]
WebSockets: [0.6, 0.6]
Kafka Pull: [0.9, 0.9]
- Long polling provides a simple way to add real-time features to existing HTTP-based systems
- WebSockets offer the best performance for truly interactive, bidirectional applications
- Kafka’s pull model excels in high-throughput, distributed systems where scalability and fault tolerance matter most
Each approach represents a different trade-off between simplicity, performance, and scalability. Understanding these trade-offs helps architects choose the right pattern for their specific use case.
The common thread is that they all maintain long-lived TCP connections with kernels waiting for interrupts—the difference lies in how they manage those connections and handle the conversation between client and server.