Day 09: Thread vs Process Comparison - Implementing Concurrent Systems in C
Table of Contents
- Introduction
- Core Concepts
- Memory Architecture Comparison
- Performance Analysis
- Communication Mechanisms
- Resource Management
- Implementation Examples
- Use Case Analysis
- Practical Demonstrations
- Benchmarking
- Sequence Diagrams
- Further Reading
- Conclusion
- References
1. Introduction
Understanding the differences between threads and processes is crucial for designing efficient concurrent applications. This article provides a detailed comparison of threads and processes, focusing on their implementation, performance characteristics, and appropriate use cases.
2. Core Concepts
Fundamental Differences
-
Memory Space Memory space in processes is completely independent and isolated. Each process has its own address space, including code, data, and heap segments. For example, if Process A has a variable ‘x’ at address 0x1000, it is entirely different from Process B’s variable ‘x’ at the same address.
-
Resource Ownership Processes own and control all their resources independently. When a process creates a file handle, that handle cannot be directly accessed by other processes without explicit sharing mechanisms. Threads, however, share resources within the same process, making resource sharing more straightforward.
-
Context Switching Overhead Process context switching requires saving and loading entire memory maps, cache contents, and CPU registers. Thread context switching only needs to save and restore CPU registers and stack pointers, making it significantly lighter.
-
Creation Time Creating a new process involves duplicating the entire parent process’s memory space and resources. Thread creation only requires allocating a new stack and thread-specific data structures. Here’s a demonstration:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h>
#include <unistd.h>
#include <sys/wait.h>
// Timing structure
typedef struct {
struct timeval start;
struct timeval end;
} timing_t;
// Function to measure process creation time
void measure_process_creation() {
timing_t timing;
gettimeofday(&timing.start, NULL);
pid_t pid = fork();
if (pid == 0) {
// Child process
exit(0);
} else {
// Parent process
wait(NULL);
}
gettimeofday(&timing.end, NULL);
long microseconds = (timing.end.tv_sec - timing.start.tv_sec) * 1000000 +
(timing.end.tv_usec - timing.start.tv_usec);
printf("Process creation time: %ld microseconds\n", microseconds);
}
// Function for thread creation measurement
void* thread_function(void* arg) {
return NULL;
}
void measure_thread_creation() {
timing_t timing;
pthread_t thread;
gettimeofday(&timing.start, NULL);
pthread_create(&thread, NULL, thread_function, NULL);
pthread_join(thread, NULL);
gettimeofday(&timing.end, NULL);
long microseconds = (timing.end.tv_sec - timing.start.tv_sec) * 1000000 +
(timing.end.tv_usec - timing.start.tv_usec);
printf("Thread creation time: %ld microseconds\n", microseconds);
}
int main() {
measure_process_creation();
measure_thread_creation();
return 0;
}
3. Memory Architecture Comparison
Memory Layout Analysis
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/mman.h>
// Shared data structure
typedef struct {
int process_value;
int thread_value;
} shared_data_t;
// Global variables
shared_data_t* shared_memory;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void* thread_function(void* arg) {
// Thread can access process memory directly
shared_memory->thread_value++;
return NULL;
}
int main() {
// Create shared memory for processes
shared_memory = mmap(NULL, sizeof(shared_data_t),
PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
shared_memory->process_value = 0;
shared_memory->thread_value = 0;
// Create process
pid_t pid = fork();
if (pid == 0) {
// Child process
shared_memory->process_value++;
exit(0);
} else {
// Parent process
pthread_t thread;
pthread_create(&thread, NULL, thread_function, NULL);
pthread_join(thread, NULL);
wait(NULL);
printf("Process value: %d\n", shared_memory->process_value);
printf("Thread value: %d\n", shared_memory->thread_value);
munmap(shared_memory, sizeof(shared_data_t));
}
return 0;
}
4. Performance Analysis
CPU Utilization
- Process Scheduling Overhead Processes require more CPU time for context switching due to memory management unit (MMU) updates and TLB flushes. Here’s a benchmark:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h>
#include <unistd.h>
#define NUM_ITERATIONS 1000000
void measure_context_switch_overhead() {
int pipe_fd[2];
pipe(pipe_fd);
struct timeval start, end;
char buffer[1];
gettimeofday(&start, NULL);
pid_t pid = fork();
if (pid == 0) {
// Child process
for (int i = 0; i < NUM_ITERATIONS; i++) {
read(pipe_fd[0], buffer, 1);
write(pipe_fd[1], "x", 1);
}
exit(0);
} else {
// Parent process
for (int i = 0; i < NUM_ITERATIONS; i++) {
write(pipe_fd[1], "x", 1);
read(pipe_fd[0], buffer, 1);
}
}
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
printf("Average context switch time: %f microseconds\n",
(float)microseconds / (NUM_ITERATIONS * 2));
}
int main() {
measure_context_switch_overhead();
return 0;
}
- Memory Access Patterns Threads share the same address space, leading to better cache utilization. Here’s a demonstration:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h>
#define ARRAY_SIZE 10000000
#define NUM_THREADS 4
double* shared_array;
void* thread_function(void* arg) {
int thread_id = *(int*)arg;
int chunk_size = ARRAY_SIZE / NUM_THREADS;
int start = thread_id * chunk_size;
int end = start + chunk_size;
for (int i = start; i < end; i++) {
shared_array[i] = shared_array[i] * 2.0;
}
return NULL;
}
int main() {
shared_array = malloc(ARRAY_SIZE * sizeof(double));
pthread_t threads[NUM_THREADS];
int thread_ids[NUM_THREADS];
// Initialize array
for (int i = 0; i < ARRAY_SIZE; i++) {
shared_array[i] = (double)i;
}
struct timeval start, end;
gettimeofday(&start, NULL);
// Create threads
for (int i = 0; i < NUM_THREADS; i++) {
thread_ids[i] = i;
pthread_create(&threads[i], NULL, thread_function, &thread_ids[i]);
}
// Wait for threads
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
printf("Thread processing time: %ld microseconds\n", microseconds);
free(shared_array);
return 0;
}
5. Communication Mechanisms
Inter-Process Communication (IPC)
- Pipes and Named Pipes Processes communicate through pipes, which require system calls and data copying. Example:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define BUFFER_SIZE 1024
void demonstrate_pipe_communication() {
int pipe_fd[2];
char buffer[BUFFER_SIZE];
if (pipe(pipe_fd) == -1) {
perror("pipe");
exit(1);
}
pid_t pid = fork();
if (pid == 0) {
// Child process
close(pipe_fd[1]); // Close write end
ssize_t bytes_read = read(pipe_fd[0], buffer, BUFFER_SIZE);
printf("Child received: %s\n", buffer);
close(pipe_fd[0]);
exit(0);
} else {
// Parent process
close(pipe_fd[0]); // Close read end
const char* message = "Hello from parent!";
write(pipe_fd[1], message, strlen(message) + 1);
close(pipe_fd[1]);
wait(NULL);
}
}
int main() {
demonstrate_pipe_communication();
return 0;
}
- Shared Memory Processes can share memory regions for faster communication:
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define SHM_NAME "/my_shm"
#define SHM_SIZE 1024
void demonstrate_shared_memory() {
int shm_fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);
ftruncate(shm_fd, SHM_SIZE);
void* shm_ptr = mmap(NULL, SHM_SIZE,
PROT_READ | PROT_WRITE,
MAP_SHARED, shm_fd, 0);
pid_t pid = fork();
if (pid == 0) {
// Child process
sleep(1); // Ensure parent writes first
printf("Child read: %s\n", (char*)shm_ptr);
exit(0);
} else {
// Parent process
sprintf(shm_ptr, "Hello from shared memory!");
wait(NULL);
munmap(shm_ptr, SHM_SIZE);
shm_unlink(SHM_NAME);
}
}
int main() {
demonstrate_shared_memory();
return 0;
}
Thread Communication
Threads can communicate directly through shared memory:
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int shared_data = 0;
int data_ready = 0;
void* producer(void* arg) {
pthread_mutex_lock(&mutex);
shared_data = 42;
data_ready = 1;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
return NULL;
}
void* consumer(void* arg) {
pthread_mutex_lock(&mutex);
while (!data_ready) {
pthread_cond_wait(&cond, &mutex);
}
printf("Received: %d\n", shared_data);
pthread_mutex_unlock(&mutex);
return NULL;
}
int main() {
pthread_t prod_thread, cons_thread;
pthread_create(&cons_thread, NULL, consumer, NULL);
pthread_create(&prod_thread, NULL, producer, NULL);
pthread_join(prod_thread, NULL);
pthread_join(cons_thread, NULL);
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
return 0;
}
6. Resource Management
Process Resources
Each process maintains its own:
- File descriptors
- Memory mappings
- Signal handlers
- Process ID
- User and group IDs
Thread Resources
Threads share:
- Address space
- File descriptors
- Signal handlers
- Current working directory But have their own:
- Stack
- Thread ID
- Signal mask
- errno variable
7. Implementation Examples
Here’s a comprehensive example showing both process and thread implementations for the same task:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/time.h>
#define ARRAY_SIZE 10000000
#define NUM_WORKERS 4
// Shared data structure
typedef struct {
double* array;
int start;
int end;
} work_unit_t;
// Thread worker function
void* thread_worker(void* arg) {
work_unit_t* unit = (work_unit_t*)arg;
for (int i = unit->start; i < unit->end; i++) {
unit->array[i] = unit->array[i] * 2.0;
}
return NULL;
}
// Process worker function
void process_worker(double* array, int start, int end) {
for (int i = start; i < end; i++) {
array[i] = array[i] * 2.0;
}
}
// Thread implementation
void thread_implementation() {
double* array = malloc(ARRAY_SIZE * sizeof(double));
pthread_t threads[NUM_WORKERS];
work_unit_t units[NUM_WORKERS];
// Initialize array
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = (double)i;
}
struct timeval start, end;
gettimeofday(&start, NULL);
// Create threads
int chunk_size = ARRAY_SIZE / NUM_WORKERS;
for (int i = 0; i < NUM_WORKERS; i++) {
units[i].array = array;
units[i].start = i * chunk_size;
units[i].end = (i == NUM_WORKERS - 1) ? ARRAY_SIZE : (i + 1) * chunk_size;
pthread_create(&threads[i], NULL, thread_worker, &units[i]);
}
// Wait for threads
for (int i = 0; i < NUM_WORKERS; i++) {
pthread_join(threads[i], NULL);
}
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec);
printf("Thread implementation time: %ld microseconds\n", microseconds);
free(array);
}
// Process implementation
void process_implementation() {
double* array = mmap(NULL, ARRAY_SIZE * sizeof(double),
PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
// Initialize array
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = (double)i;
}
struct timeval start, end;
gettimeofday(&start, NULL);
// Create processes
int chunk_size = ARRAY_SIZE / NUM_WORKERS;
for (int i = 0; i < NUM_WORKERS; i++) {
pid_t pid = fork();
if (pid == 0) {
// Child process
int start = i * chunk_size;
int end = (i == NUM_WORKERS - 1) ? ARRAY_SIZE : (i + 1) * chunk_size;
process_worker(array, start, end);
exit(0);
}
}
// Wait for all child processes
for (int i = 0; i < NUM_WORKERS; i++) {
wait(NULL);
}
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
printf("Process implementation time: %ld microseconds\n", microseconds);
munmap(array, ARRAY_SIZE * sizeof(double));
}
int main() {
printf("Running thread implementation...\n");
thread_implementation();
printf("\nRunning process implementation...\n");
process_implementation();
return 0;
}
8. Use Case Analysis
When to Use Processes
-
Isolation Requirements Processes are ideal when you need strong isolation between components. For example, web browsers use separate processes for each tab to prevent a crash in one tab from affecting others.
-
Security Concerns When handling sensitive data, processes provide better security through memory isolation. Example use case:
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
void secure_processing() {
// Sensitive data in isolated process
char* sensitive_data = mmap(NULL, 4096,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
sprintf(sensitive_data, "SECRET_KEY=12345");
// Process the data in isolation
pid_t pid = fork();
if (pid == 0) {
// Child process - isolated memory space
printf("Child process handling sensitive data\n");
// Process sensitive_data here
munmap(sensitive_data, 4096);
exit(0);
} else {
wait(NULL);
munmap(sensitive_data, 4096);
}
}
When to Use Threads
- Shared Resource Access Threads are better when multiple execution units need to share resources frequently:
#include <pthread.h>
#include <stdio.h>
typedef struct {
int* shared_counter;
pthread_mutex_t* mutex;
} shared_resource_t;
void* increment_counter(void* arg) {
shared_resource_t* resource = (shared_resource_t*)arg;
for (int i = 0; i < 1000000; i++) {
pthread_mutex_lock(resource->mutex);
(*resource->shared_counter)++;
pthread_mutex_unlock(resource->mutex);
}
return NULL;
}
void demonstrate_shared_resource() {
int counter = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
shared_resource_t resource = {&counter, &mutex};
pthread_t threads[4];
for (int i = 0; i < 4; i++) {
pthread_create(&threads[i], NULL, increment_counter, &resource);
}
for (int i = 0; i < 4; i++) {
pthread_join(threads[i], NULL);
}
printf("Final counter value: %d\n", counter);
pthread_mutex_destroy(&mutex);
}
- Real-time Communication Threads are efficient for scenarios requiring frequent communication:
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t data_cond = PTHREAD_COND_INITIALIZER;
int data_ready = 0;
double shared_data = 0.0;
void* real_time_producer(void* arg) {
for (int i = 0; i < 10; i++) {
pthread_mutex_lock(&mutex);
shared_data = i * 1.5;
data_ready = 1;
pthread_cond_signal(&data_cond);
pthread_mutex_unlock(&mutex);
usleep(100000); // 100ms
}
return NULL;
}
void* real_time_consumer(void* arg) {
while (1) {
pthread_mutex_lock(&mutex);
while (!data_ready) {
pthread_cond_wait(&data_cond, &mutex);
}
printf("Received data: %f\n", shared_data);
data_ready = 0;
pthread_mutex_unlock(&mutex);
}
return NULL;
}
9. Practical Demonstrations
Here’s a real-world example comparing process and thread performance for matrix multiplication:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <sys/time.h>
#define MATRIX_SIZE 1000
#define NUM_WORKERS 4
typedef struct {
double* a;
double* b;
double* c;
int start_row;
int end_row;
} matrix_work_t;
void* thread_matrix_multiply(void* arg) {
matrix_work_t* work = (matrix_work_t*)arg;
for (int i = work->start_row; i < work->end_row; i++) {
for (int j = 0; j < MATRIX_SIZE; j++) {
double sum = 0.0;
for (int k = 0; k < MATRIX_SIZE; k++) {
sum += work->a[i * MATRIX_SIZE + k] *
work->b[k * MATRIX_SIZE + j];
}
work->c[i * MATRIX_SIZE + j] = sum;
}
}
return NULL;
}
void process_matrix_multiply(double* a, double* b, double* c,
int start_row, int end_row) {
for (int i = start_row; i < end_row; i++) {
for (int j = 0; j < MATRIX_SIZE; j++) {
double sum = 0.0;
for (int k = 0; k < MATRIX_SIZE; k++) {
sum += a[i * MATRIX_SIZE + k] *
b[k * MATRIX_SIZE + j];
}
c[i * MATRIX_SIZE + j] = sum;
}
}
}
void compare_performance() {
// Allocate matrices
size_t matrix_bytes = MATRIX_SIZE * MATRIX_SIZE * sizeof(double);
double* a = mmap(NULL, matrix_bytes,
PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
double* b = mmap(NULL, matrix_bytes,
PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
double* c = mmap(NULL, matrix_bytes,
PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
// Initialize matrices
for (int i = 0; i < MATRIX_SIZE * MATRIX_SIZE; i++) {
a[i] = (double)rand() / RAND_MAX;
b[i] = (double)rand() / RAND_MAX;
}
struct timeval start, end;
// Thread implementation
gettimeofday(&start, NULL);
pthread_t threads[NUM_WORKERS];
matrix_work_t thread_work[NUM_WORKERS];
int rows_per_worker = MATRIX_SIZE / NUM_WORKERS;
for (int i = 0; i < NUM_WORKERS; i++) {
thread_work[i].a = a;
thread_work[i].b = b;
thread_work[i].c = c;
thread_work[i].start_row = i * rows_per_worker;
thread_work[i].end_row = (i == NUM_WORKERS - 1) ?
MATRIX_SIZE : (i + 1) * rows_per_worker;
pthread_create(&threads[i], NULL,
thread_matrix_multiply, &thread_work[i]);
}
for (int i = 0; i < NUM_WORKERS; i++) {
pthread_join(threads[i], NULL);
}
gettimeofday(&end, NULL);
long thread_time = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
// Process implementation
gettimeofday(&start, NULL);
for (int i = 0; i < NUM_WORKERS; i++) {
pid_t pid = fork();
if (pid == 0) {
int start_row = i * rows_per_worker;
int end_row = (i == NUM_WORKERS - 1) ?
MATRIX_SIZE : (i + 1) * rows_per_worker;
process_matrix_multiply(a, b, c, start_row, end_row);
exit(0);
}
}
for (int i = 0; i < NUM_WORKERS; i++) {
wait(NULL);
}
gettimeofday(&end, NULL);
long process_time = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
printf("Thread implementation time: %ld microseconds\n", thread_time);
printf("Process implementation time: %ld microseconds\n", process_time);
// Clean up
munmap(a, matrix_bytes);
munmap(b, matrix_bytes);
munmap(c, matrix_bytes);
}
int main() {
compare_performance();
return 0;
}
10. Benchmarking
Here’s a simple benchmarking tool to compare thread and process performance:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/time.h>
#define NUM_ITERATIONS 1000000
#define NUM_RUNS 10
typedef struct {
long thread_times[NUM_RUNS];
long process_times[NUM_RUNS];
} benchmark_results_t;
void* thread_work(void* arg) {
// Simulate some work
double result = 0.0;
for (int i = 0; i < NUM_ITERATIONS; i++) {
result += i * 1.5;
}
return NULL;
}
void process_work() {
double result = 0.0;
for (int i = 0; i < NUM_ITERATIONS; i++) {
result += i * 1.5;
}
}
benchmark_results_t run_benchmarks() {
benchmark_results_t results;
struct timeval start, end;
for (int run = 0; run < NUM_RUNS; run++) {
// Thread benchmark
gettimeofday(&start, NULL);
pthread_t thread;
pthread_create(&thread, NULL, thread_work, NULL);
pthread_join(thread, NULL);
gettimeofday(&end, NULL);
results.thread_times[run] = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
// Process benchmark
gettimeofday(&start, NULL);
pid_t pid = fork();
if (pid == 0) {
process_work();
exit(0);
} else {
wait(NULL);
}
gettimeofday(&end, NULL);
results.process_times[run] = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
}
return results;
}
void analyze_results(benchmark_results_t results) {
double thread_avg = 0.0, process_avg = 0.0;
long thread_min = results.thread_times[0];
long thread_max = results.thread_times[0];
long process_min = results.process_times[0];
long process_max = results.process_times[0];
for (int i = 0; i < NUM_RUNS; i++) {
thread_avg += results.thread_times[i];
process_avg += results.process_times[i];
if (results.thread_times[i] < thread_min)
thread_min = results.thread_times[i];
if (results.thread_times[i] > thread_max)
thread_max = results.thread_times[i];
if (results.process_times[i] < process_min)
process_min = results.process_times[i];
if (results.process_times[i] > process_max)
process_max = results.process_times[i];
}
thread_avg /= NUM_RUNS;
process_avg /= NUM_RUNS;
printf("Thread Performance:\n");
printf(" Average: %.2f microseconds\n", thread_avg);
printf(" Min: %ld microseconds\n", thread_min);
printf(" Max: %ld microseconds\n", thread_max);
printf("\nProcess Performance:\n");
printf(" Average: %.2f microseconds\n", process_avg);
printf(" Min: %ld microseconds\n", process_min);
printf(" Max: %ld microseconds\n", process_max);
}
int main() {
printf("Running benchmarks...\n");
benchmark_results_t results = run_benchmarks();
printf("\nBenchmark Results:\n");
analyze_results(results);
return 0;
}
Here are diagrams which can help you visualize the lifecycle and interaction patterns of threads and processes:

Thread interaction pattern:
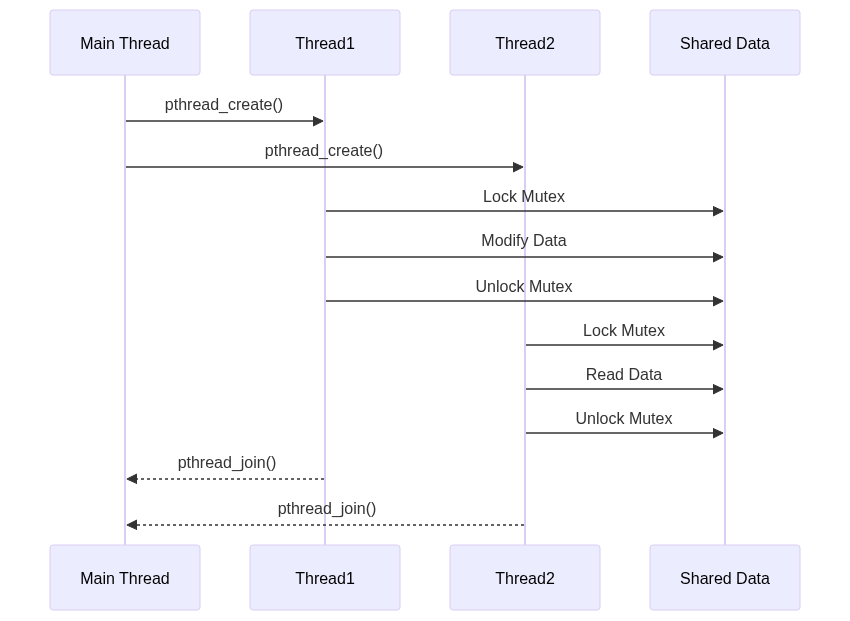
12. Further Reading
- Books
- “Operating System Concepts” by Silberschatz, Galvin, and Gagne
- “Advanced Programming in the UNIX Environment” by W. Richard Stevens
- “The Linux Programming Interface” by Michael Kerrisk
- Online Resources
- Linux man pages:
man 7 pthreads,man 2 fork - POSIX Threads Programming Guide
- Linux Process vs Thread Performance
- Linux man pages:
13. Conclusion
The choice between threads and processes depends on various factors:
- Memory Usage
- Processes have higher memory overhead due to separate address spaces
- Threads share memory space, making them more memory-efficient
- Communication Overhead
- Inter-process communication is more complex and slower
- Thread communication is faster due to shared memory
- Isolation and Security
- Processes provide better isolation and security
- Threads are more vulnerable to errors affecting the entire process
- Development Complexity
- Process-based programs are often simpler to debug
- Thread-based programs require careful synchronization
Here’s a decision-making helper function:
typedef enum {
REQUIREMENT_ISOLATION,
REQUIREMENT_PERFORMANCE,
REQUIREMENT_COMMUNICATION,
REQUIREMENT_SECURITY
} requirement_t;
typedef struct {
int isolation_weight;
int performance_weight;
int communication_weight;
int security_weight;
} requirements_t;
const char* suggest_implementation(requirements_t reqs) {
int process_score = 0;
int thread_score = 0;
// Calculate scores based on requirements
process_score += reqs.isolation_weight * 9; // Processes excel at isolation
process_score += reqs.performance_weight * 5; // Moderate performance
process_score += reqs.communication_weight * 3; // Poor for communication
process_score += reqs.security_weight * 9; // Excellent security
thread_score += reqs.isolation_weight * 3; // Poor isolation
thread_score += reqs.performance_weight * 8; // Excellent performance
thread_score += reqs.communication_weight * 9; // Excellent communication
thread_score += reqs.security_weight * 4; // Moderate security
return (process_score > thread_score) ?
"Use Processes" : "Use Threads";
}
// Example usage:
void demonstrate_decision_making() {
requirements_t reqs = {
.isolation_weight = 8, // High importance
.performance_weight = 5, // Medium importance
.communication_weight = 3, // Low importance
.security_weight = 9 // Critical importance
};
printf("Suggestion: %s\n", suggest_implementation(reqs));
}
14. References
- IEEE POSIX Standard (IEEE Std 1003.1-2017)
- Linux Kernel Documentation (processes and threads)
- GNU C Library Manual
- “Modern Operating Systems” by Andrew S. Tanenbaum
- “Understanding the Linux Kernel” by Daniel P. Bovet and Marco Cesati
Final Thoughts
Understanding the differences between threads and processes is crucial for system design. Here’s a quick reference implementation showing both approaches:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/time.h>
#include <string.h>
#include <sys/mman.h>
#include <fcntl.h>
#define NUM_ITEMS 1000
#define SHARED_MEM_NAME "/shared_mem_example"
// Requirements structure for decision making
typedef struct {
int isolation_weight;
int performance_weight;
int communication_weight;
int security_weight;
} requirements_t;
// Common data structure for both approaches
typedef struct {
int* data;
int start_index;
int end_index;
} work_data_t;
// Common interface for both approaches
typedef struct {
void (*initialize)(void* processor_data);
void (*process_data)(void* processor_data, work_data_t* work);
void (*cleanup)(void* processor_data);
void* processor_data;
} concurrent_processor_t;
// Thread-based implementation
typedef struct {
pthread_t* threads;
int num_threads;
int* shared_data;
pthread_mutex_t mutex;
work_data_t* work_units;
} thread_processor_t;
// Process-based implementation
typedef struct {
pid_t* processes;
int num_processes;
int* shared_memory;
int shm_fd;
work_data_t* work_units;
} process_processor_t;
// Decision making function
const char* suggest_implementation(requirements_t reqs) {
int process_score = 0;
int thread_score = 0;
process_score += reqs.isolation_weight * 9;
process_score += reqs.performance_weight * 5;
process_score += reqs.communication_weight * 3;
process_score += reqs.security_weight * 9;
thread_score += reqs.isolation_weight * 3;
thread_score += reqs.performance_weight * 8;
thread_score += reqs.communication_weight * 9;
thread_score += reqs.security_weight * 4;
return (process_score > thread_score) ? "Use Processes" : "Use Threads";
}
// Thread worker function
void* thread_worker(void* arg) {
work_data_t* work = (work_data_t*)arg;
for (int i = work->start_index; i < work->end_index; i++) {
work->data[i] *= 2; // Simple data processing
}
return NULL;
}
// Thread implementation functions
void thread_initialize(void* processor_data) {
thread_processor_t* tp = (thread_processor_t*)processor_data;
tp->shared_data = malloc(NUM_ITEMS * sizeof(int));
tp->work_units = malloc(tp->num_threads * sizeof(work_data_t));
// Initialize data
for (int i = 0; i < NUM_ITEMS; i++) {
tp->shared_data[i] = i;
}
pthread_mutex_init(&tp->mutex, NULL);
}
void thread_process_data(void* processor_data, work_data_t* work) {
thread_processor_t* tp = (thread_processor_t*)processor_data;
int items_per_thread = NUM_ITEMS / tp->num_threads;
// Create and start threads
for (int i = 0; i < tp->num_threads; i++) {
tp->work_units[i].data = tp->shared_data;
tp->work_units[i].start_index = i * items_per_thread;
tp->work_units[i].end_index = (i == tp->num_threads - 1) ?
NUM_ITEMS : (i + 1) * items_per_thread;
pthread_create(&tp->threads[i], NULL, thread_worker, &tp->work_units[i]);
}
// Wait for threads to complete
for (int i = 0; i < tp->num_threads; i++) {
pthread_join(tp->threads[i], NULL);
}
}
void thread_cleanup(void* processor_data) {
thread_processor_t* tp = (thread_processor_t*)processor_data;
pthread_mutex_destroy(&tp->mutex);
free(tp->shared_data);
free(tp->work_units);
free(tp->threads);
free(tp);
}
// Process worker function
void process_worker(work_data_t* work) {
for (int i = work->start_index; i < work->end_index; i++) {
work->data[i] *= 2; // Simple data processing
}
exit(0);
}
// Process implementation functions
void process_initialize(void* processor_data) {
process_processor_t* pp = (process_processor_t*)processor_data;
// Create shared memory
pp->shm_fd = shm_open(SHARED_MEM_NAME, O_CREAT | O_RDWR, 0666);
ftruncate(pp->shm_fd, NUM_ITEMS * sizeof(int));
pp->shared_memory = mmap(NULL, NUM_ITEMS * sizeof(int),
PROT_READ | PROT_WRITE,
MAP_SHARED, pp->shm_fd, 0);
pp->work_units = malloc(pp->num_processes * sizeof(work_data_t));
// Initialize data
for (int i = 0; i < NUM_ITEMS; i++) {
pp->shared_memory[i] = i;
}
}
void process_process_data(void* processor_data, work_data_t* work) {
process_processor_t* pp = (process_processor_t*)processor_data;
int items_per_process = NUM_ITEMS / pp->num_processes;
// Create and start processes
for (int i = 0; i < pp->num_processes; i++) {
pp->work_units[i].data = pp->shared_memory;
pp->work_units[i].start_index = i * items_per_process;
pp->work_units[i].end_index = (i == pp->num_processes - 1) ?
NUM_ITEMS : (i + 1) * items_per_process;
pid_t pid = fork();
if (pid == 0) {
process_worker(&pp->work_units[i]);
}
pp->processes[i] = pid;
}
// Wait for processes to complete
for (int i = 0; i < pp->num_processes; i++) {
waitpid(pp->processes[i], NULL, 0);
}
}
void process_cleanup(void* processor_data) {
process_processor_t* pp = (process_processor_t*)processor_data;
munmap(pp->shared_memory, NUM_ITEMS * sizeof(int));
shm_unlink(SHARED_MEM_NAME);
free(pp->work_units);
free(pp->processes);
free(pp);
}
concurrent_processor_t* create_processor(int is_threaded, int num_workers) {
concurrent_processor_t* processor = malloc(sizeof(concurrent_processor_t));
if (is_threaded) {
thread_processor_t* tp = malloc(sizeof(thread_processor_t));
tp->threads = malloc(num_workers * sizeof(pthread_t));
tp->num_threads = num_workers;
processor->initialize = thread_initialize;
processor->process_data = thread_process_data;
processor->cleanup = thread_cleanup;
processor->processor_data = tp;
} else {
process_processor_t* pp = malloc(sizeof(process_processor_t));
pp->processes = malloc(num_workers * sizeof(pid_t));
pp->num_processes = num_workers;
processor->initialize = process_initialize;
processor->process_data = process_process_data;
processor->cleanup = process_cleanup;
processor->processor_data = pp;
}
return processor;
}
void print_results(int* data, int size) {
printf("First 10 results: ");
for (int i = 0; i < 10 && i < size; i++) {
printf("%d ", data[i]);
}
printf("\n");
}
int main() {
// Choose implementation based on requirements
requirements_t reqs = {
.isolation_weight = 5,
.performance_weight = 8,
.communication_weight = 7,
.security_weight = 4
};
const char* suggestion = suggest_implementation(reqs);
printf("Based on requirements, suggestion: %s\n", suggestion);
int use_threads = (strcmp(suggestion, "Use Threads") == 0);
concurrent_processor_t* processor = create_processor(use_threads, 4);
// Initialize the processor
processor->initialize(processor->processor_data);
// Process data
work_data_t work = {0}; // Dummy work data, actual work units are created inside
struct timeval start, end;
gettimeofday(&start, NULL);
processor->process_data(processor->processor_data, &work);
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000 +
(end.tv_usec - start.tv_usec);
// Print results
if (use_threads) {
thread_processor_t* tp = (thread_processor_t*)processor->processor_data;
print_results(tp->shared_data, NUM_ITEMS);
} else {
process_processor_t* pp = (process_processor_t*)processor->processor_data;
print_results(pp->shared_memory, NUM_ITEMS);
}
printf("Processing time: %ld microseconds\n", microseconds);
// Cleanup
processor->cleanup(processor->processor_data);
free(processor);
return 0;
}