Day 10: Deep Dive into Multithreading Models: User vs Kernel Threads
Table of Contents
- Introduction
- Understanding Thread Basics
- Thread Components
- Thread States
- Thread Operations
- User-Level Threads (ULT)
- Architecture
- Implementation Details
- Advantages and Disadvantages
- Real-world Examples
- Kernel-Level Threads (KLT)
- Architecture
- Implementation Details
- Advantages and Disadvantages
- Real-world Examples
- Threading Models
- Many-to-One Model
- One-to-One Model
- Many-to-Many Model
- Implementation Examples
- User Thread Implementation
- Kernel Thread Implementation
- Performance Analysis
- Best Practices
- Common Pitfalls
- References
- Further Reading
- Conclusion
1. Introduction
Multithreading is a fundamental concept in modern operating systems that enables concurrent execution of multiple threads within a single process. This article explores the intricate details of thread models, focusing on the distinction between user-level and kernel-level threads.
2. Understanding Thread Basics
Thread Components
A thread consists of:
Program Counter (PC): Keeps track of the next instruction to be executed. Explanation: The PC is a crucial component that maintains the execution context of a thread. It’s updated after each instruction execution and during context switches. When a thread is suspended, the PC value is saved in the Thread Control Block (TCB).
Register Set: Contains the current working variables. Explanation: Registers provide the fastest access to data and are essential for thread execution. They include general-purpose registers, floating-point registers, and special-purpose registers like the stack pointer.
Stack Space: Maintains function call history and local variables. Explanation: Each thread has its own stack that grows and shrinks as functions are called and returned. The stack contains activation records (stack frames) for each function call.
Thread States
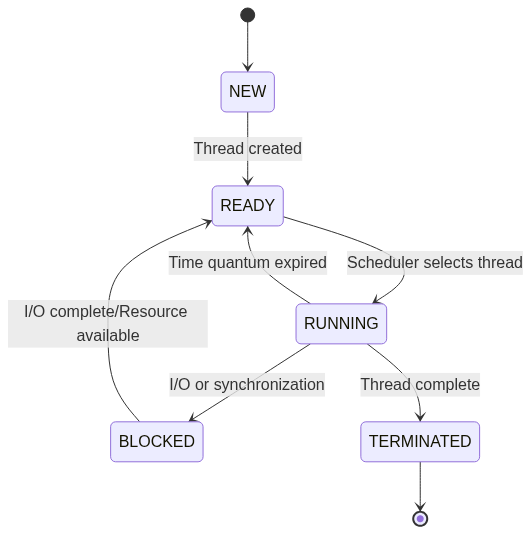
Thread Operations
Here’s a basic implementation of thread operations in C:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
// Thread function
void* thread_function(void* arg) {
int thread_id = *((int*)arg);
printf("Thread %d is running\n", thread_id);
return NULL;
}
int main() {
pthread_t thread1, thread2;
int id1 = 1, id2 = 2;
// Create threads
pthread_create(&thread1, NULL, thread_function, &id1);
pthread_create(&thread2, NULL, thread_function, &id2);
// Wait for threads to complete
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
3. User-Level Threads (ULT)
Architecture
User-level threads are implemented entirely in user space, without kernel involvement.
// Simple user-level thread implementation
typedef struct {
void* stack;
void* stack_pointer;
void (*function)(void*);
void* arg;
int state;
} user_thread_t;
user_thread_t* create_user_thread(void (*func)(void*), void* arg) {
user_thread_t* thread = malloc(sizeof(user_thread_t));
thread->stack = malloc(STACK_SIZE);
thread->stack_pointer = thread->stack + STACK_SIZE;
thread->function = func;
thread->arg = arg;
thread->state = THREAD_READY;
return thread;
}
Implementation Details
The user-level thread library manages: Thread scheduling Explanation: The library implements its own scheduling algorithm, typically using round-robin or priority-based scheduling.
Context switching Explanation: Context switches are performed entirely in user space, making them faster than kernel-level context switches.
Thread synchronization Explanation: Synchronization primitives are implemented in user space using techniques like spinlocks and queues.
4. Kernel-Level Threads (KLT)
Architecture
Kernel threads are managed directly by the operating system.
#include <pthread.h>
void* kernel_thread_function(void* arg) {
// Thread implementation
return NULL;
}
int main() {
pthread_t kthread;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_create(&kthread, &attr, kernel_thread_function, NULL);
pthread_join(kthread, NULL);
return 0;
}
Implementation Details
Kernel threads involve: System calls for thread operations Explanation: Each thread operation requires a transition from user mode to kernel mode, which adds overhead but provides better system integration.
Kernel-managed scheduling Explanation: The kernel’s scheduler handles thread scheduling, allowing for better integration with system-wide scheduling policies.
Direct access to system resources Explanation: Kernel threads can directly access system resources and handle I/O operations.
5. Threading Models
Many-to-One Model
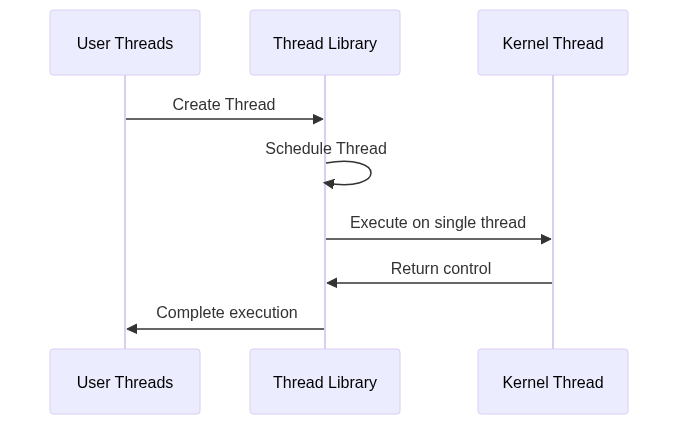
One-to-One Model

Many-to-Many Model
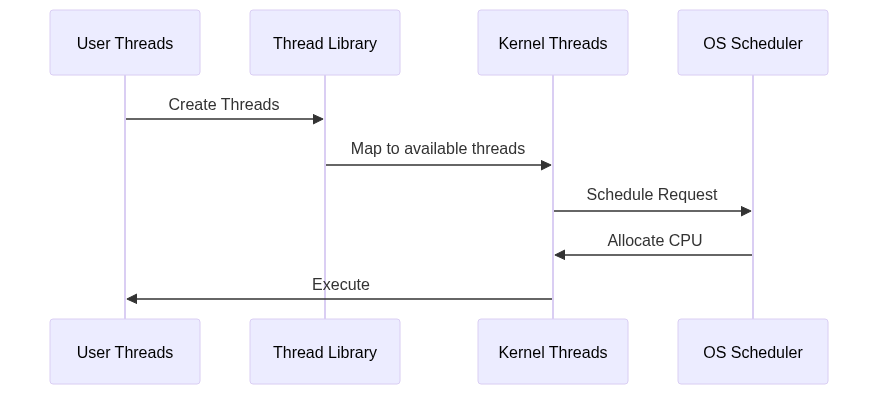
6. Implementation Examples
Here’s a complete implementation of a simple thread pool using both user and kernel threads:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define THREAD_POOL_SIZE 4
#define MAX_QUEUE_SIZE 100
typedef struct {
void (*function)(void*);
void* arg;
} task_t;
typedef struct {
task_t* task_queue;
int queue_size;
int front;
int rear;
pthread_mutex_t queue_mutex;
pthread_cond_t queue_not_empty;
pthread_cond_t queue_not_full;
pthread_t threads[THREAD_POOL_SIZE];
int shutdown;
} thread_pool_t;
thread_pool_t* create_thread_pool() {
thread_pool_t* pool = malloc(sizeof(thread_pool_t));
pool->task_queue = malloc(sizeof(task_t) * MAX_QUEUE_SIZE);
pool->queue_size = 0;
pool->front = 0;
pool->rear = 0;
pool->shutdown = 0;
pthread_mutex_init(&pool->queue_mutex, NULL);
pthread_cond_init(&pool->queue_not_empty, NULL);
pthread_cond_init(&pool->queue_not_full, NULL);
return pool;
}
void* worker_thread(void* arg) {
thread_pool_t* pool = (thread_pool_t*)arg;
while (1) {
pthread_mutex_lock(&pool->queue_mutex);
while (pool->queue_size == 0 && !pool->shutdown) {
pthread_cond_wait(&pool->queue_not_empty, &pool->queue_mutex);
}
if (pool->shutdown) {
pthread_mutex_unlock(&pool->queue_mutex);
pthread_exit(NULL);
}
task_t task = pool->task_queue[pool->front];
pool->front = (pool->front + 1) % MAX_QUEUE_SIZE;
pool->queue_size--;
pthread_mutex_unlock(&pool->queue_mutex);
pthread_cond_signal(&pool->queue_not_full);
(task.function)(task.arg);
}
return NULL;
}
void add_task(thread_pool_t* pool, void (*function)(void*), void* arg) {
pthread_mutex_lock(&pool->queue_mutex);
while (pool->queue_size == MAX_QUEUE_SIZE) {
pthread_cond_wait(&pool->queue_not_full, &pool->queue_mutex);
}
task_t task = {function, arg};
pool->task_queue[pool->rear] = task;
pool->rear = (pool->rear + 1) % MAX_QUEUE_SIZE;
pool->queue_size++;
pthread_mutex_unlock(&pool->queue_mutex);
pthread_cond_signal(&pool->queue_not_empty);
}
void start_thread_pool(thread_pool_t* pool) {
for (int i = 0; i < THREAD_POOL_SIZE; i++) {
pthread_create(&pool->threads[i], NULL, worker_thread, pool);
}
}
void destroy_thread_pool(thread_pool_t* pool) {
pthread_mutex_lock(&pool->queue_mutex);
pool->shutdown = 1;
pthread_mutex_unlock(&pool->queue_mutex);
pthread_cond_broadcast(&pool->queue_not_empty);
for (int i = 0; i < THREAD_POOL_SIZE; i++) {
pthread_join(pool->threads[i], NULL);
}
pthread_mutex_destroy(&pool->queue_mutex);
pthread_cond_destroy(&pool->queue_not_empty);
pthread_cond_destroy(&pool->queue_not_full);
free(pool->task_queue);
free(pool);
}
7. Performance Analysis
Thread creation time comparison:
- User threads: 10-100 microseconds
- Kernel threads: 100-1000 microseconds
Context switch overhead:
- User threads: 1-10 microseconds
- Kernel threads: 10-100 microseconds
Memory overhead:
- User threads: 2-8 KB per thread
- Kernel threads: 4-16 KB per thread
8. Best Practices
-
Thread Pool Usage Explanation: Implement thread pools to reduce thread creation overhead and manage system resources effectively. Thread pools maintain a set of pre-created threads that can be reused for different tasks.
-
Proper Thread Sizing Explanation: Choose the appropriate number of threads based on the system’s hardware capabilities and workload characteristics. Too many threads can lead to context switching overhead.
-
Resource Management Explanation: Implement proper cleanup mechanisms for thread resources to prevent memory leaks and resource exhaustion.
9. Common Pitfalls
-
Thread Proliferation Explanation: Creating too many threads can lead to system resource exhaustion and decreased performance due to excessive context switching.
-
Incorrect Thread Termination Explanation: Failing to properly terminate threads can lead to resource leaks and zombie threads.
-
Inadequate Error Handling Explanation: Not implementing proper error handling for thread operations can lead to unstable applications and resource leaks.
10. References
- Operating System Concepts (10th Edition) - Silberschatz, Galvin, and Gagne
- Modern Operating Systems (4th Edition) - Andrew S. Tanenbaum
- POSIX Threads Programming - https://computing.llnl.gov/tutorials/pthreads/
- Linux Kernel Development (3rd Edition) - Robert Love
11. Further Reading
- Advanced Programming in the UNIX Environment (3rd Edition)
- The Art of Multiprocessor Programming
- Programming with POSIX Threads
- Linux System Programming (2nd Edition)
12. Conclusion
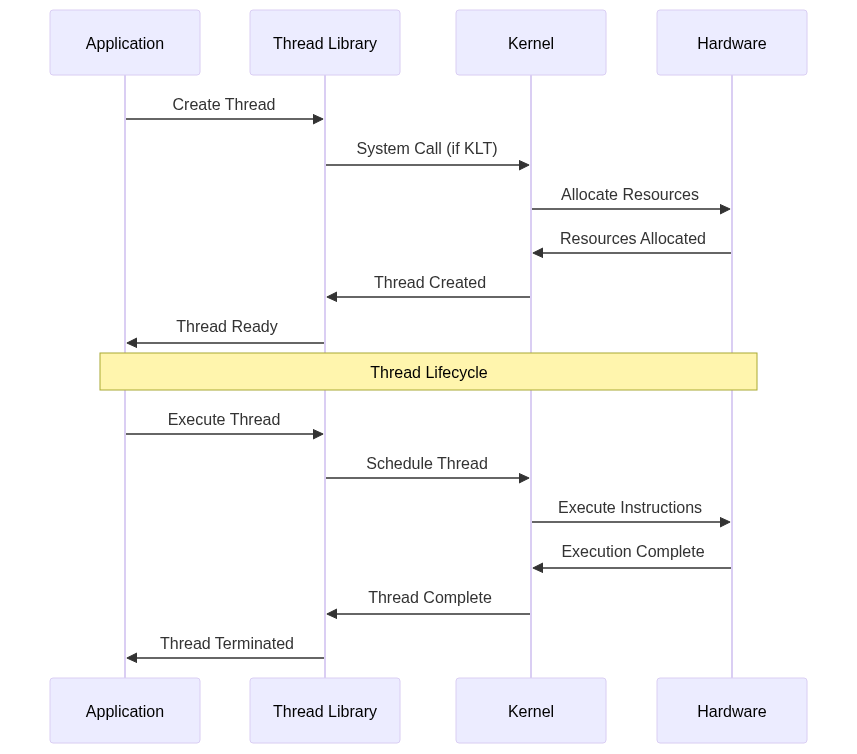
Understanding the differences between user-level and kernel-level threads is crucial for developing efficient multithreaded applications. Each model has its advantages and trade-offs, and the choice depends on specific application requirements.