Day 13: Deadlock Concepts and Prevention Strategies in Concurrent Systems
Table of Contents
- Introduction to Deadlocks
- Fundamental Deadlock Characteristics
- Conditions Leading to Deadlock
- Deadlock Detection Mechanisms
- Prevention Strategies
- Practical Implementation Example
- Theoretical Foundations of Deadlock Management
- Advanced Mitigation Techniques
- Real-world Deadlock Scenarios
- Emerging Research Directions
- Performance and Optimization Strategies
- Performance Implications
- Conclusion
Introduction to Deadlocks
Deadlock represents one of the most insidious challenges in concurrent computing, a scenario where multiple threads or processes become permanently stuck, unable to progress due to circular resource dependencies. Imagine a complex traffic intersection where four cars arrive simultaneously, each waiting for the other to move, creating a perfect standstill - this precisely mirrors the concept of a computational deadlock.
In the realm of concurrent systems, deadlocks emerge as a critical failure mode that can bring entire computer systems to a complete halt. Unlike other synchronization challenges that might cause temporary performance degradation, deadlocks represent a total system paralysis where threads are indefinitely suspended, consuming system resources without making any meaningful progress.
The complexity of deadlocks stems from their nature as emergent phenomena. They are not the result of a single point of failure but arise from the intricate interactions between multiple threads, resource allocation strategies, and synchronization mechanisms. Understanding deadlocks requires a holistic view of how computational resources are requested, allocated, and managed in parallel computing environments.
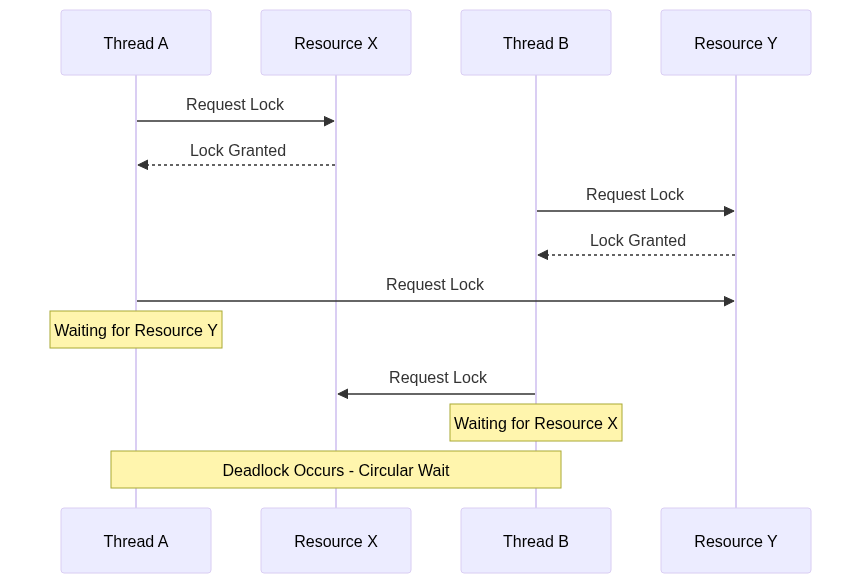
Fundamental Deadlock Characteristics
Deadlocks are characterized by four fundamental conditions that must simultaneously exist for a deadlock to occur. These conditions, first articulated by computer science pioneers, provide a framework for understanding and preventing these complex synchronization failures.
The first condition involves mutual exclusion, where resources cannot be simultaneously shared by multiple threads. This means that when a resource is allocated to one thread, it becomes unavailable to others until explicitly released. While mutual exclusion is crucial for maintaining data integrity, it also creates the potential for resource contention.
The second critical condition is the hold and wait scenario. In this situation, a thread currently holding one resource simultaneously requests additional resources. If these additional resources are already allocated to other threads, the requesting thread enters a waiting state while retaining its initial resources. This creates a potential circular dependency that can lead to systemic lockup.
No preemption represents the third fundamental deadlock condition. In a system without preemption, resources cannot be forcibly retrieved from threads that currently hold them. Once a resource is allocated, it remains with the thread until that thread voluntarily releases it. This characteristic prevents external intervention in resource allocation, potentially allowing deadlock situations to persist indefinitely.
The fourth and final condition involves circular wait, where a set of threads are waiting for resources held by each other in a circular chain. Picture a scenario where Thread A holds Resource X and wants Resource Y, Thread B holds Resource Y and wants Resource Z, and Thread C holds Resource Z but wants Resource X. This circular dependency creates a perfect deadlock scenario with no possible resolution.
Conditions Leading to Deadlock
Resource allocation strategies play a pivotal role in creating deadlock-prone systems. Complex software architectures often involve multiple shared resources, including memory segments, file handles, network connections, and synchronization primitives. Each resource allocation decision introduces potential deadlock risks.
Operating system design significantly influences deadlock susceptibility. Kernel-level resource management, thread scheduling algorithms, and inter-process communication mechanisms all contribute to the likelihood of deadlock occurrence. Modern operating systems implement increasingly sophisticated strategies to detect, prevent, and mitigate these risks.
Database systems represent a classic domain where deadlock potential is exceptionally high. Multiple transactions accessing shared data concurrently can easily create scenarios where each transaction holds resources required by others, leading to complex circular dependency chains. Transaction isolation levels and careful locking strategies become critical in managing these risks.
Deadlock Detection Mechanisms
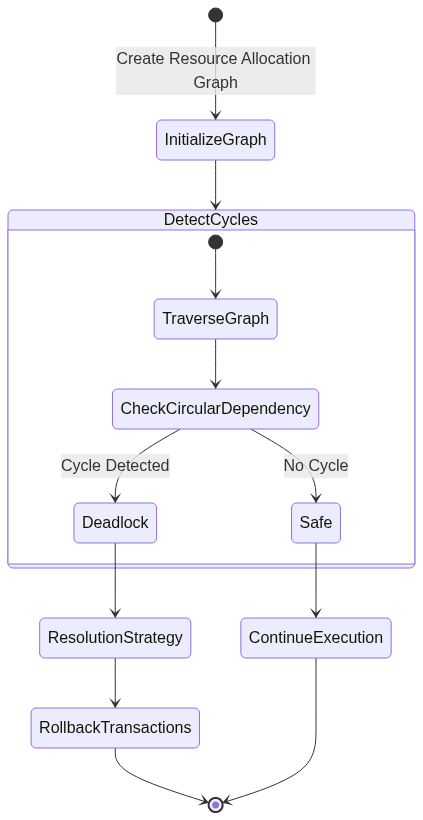
Detecting deadlocks requires sophisticated algorithmic approaches that can analyze the current state of system resources and thread interactions. Resource allocation graphs provide a powerful visualization and analysis tool, mapping out how threads and resources are interconnected.
In a resource allocation graph, threads are represented as processes, and resources are depicted as nodes. Directed edges show resource allocation and request relationships. When this graph contains a cycle, it indicates a potential deadlock scenario. Advanced detection algorithms can traverse these graphs in real-time, identifying potential deadlock situations before they fully manifest.
Timeout-based detection represents another practical approach. By implementing intelligent waiting mechanisms with predefined time limits, systems can automatically detect and resolve potential deadlocks. If a thread fails to acquire required resources within a specified duration, the system can take corrective actions such as rolling back transactions or releasing held resources.
Prevention Strategies
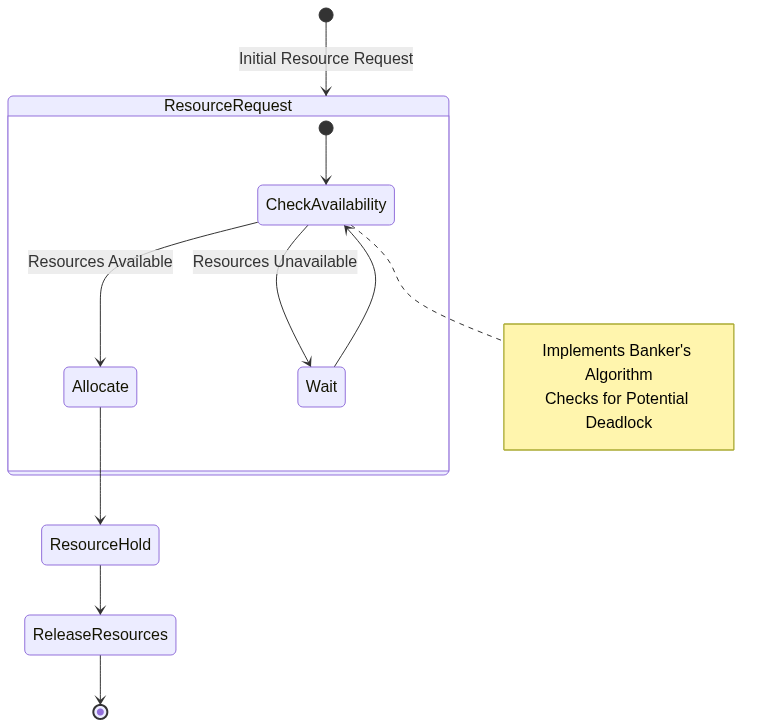
Preventing deadlocks requires a multifaceted approach that addresses the fundamental conditions that enable their occurrence. Resource ordering represents one of the most effective prevention techniques. By establishing a consistent, global order for resource acquisition, systems can mathematically prevent circular wait scenarios.
The Banker’s Algorithm emerges as a sophisticated deadlock prevention mechanism. Named after its conceptual similarity to a banking system managing limited funds, this algorithm carefully analyzes resource allocation requests. Before granting a resource, the Banker’s Algorithm simulates the entire allocation to ensure that the system can eventually return to a safe state where all threads can complete their execution.
Resource reservation and careful allocation planning provide another prevention strategy. By implementing predictive resource management techniques, systems can anticipate potential contention and proactively allocate resources to minimize deadlock risks. This approach requires deep understanding of application workload characteristics and resource utilization patterns.
Practical Implementation Example
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#define NUM_PHILOSOPHERS 5
#define LEFT(x) ((x + NUM_PHILOSOPHERS - 1) % NUM_PHILOSOPHERS)
#define RIGHT(x) ((x + 1) % NUM_PHILOSOPHERS)
pthread_mutex_t forks[NUM_PHILOSOPHERS];
pthread_t philosophers[NUM_PHILOSOPHERS];
void* philosopher_activity(void* arg) {
int philosopher_id = *(int*)arg;
int first_fork, second_fork;
// Implement resource ordering to prevent deadlock
if (philosopher_id % 2 == 0) {
first_fork = LEFT(philosopher_id);
second_fork = RIGHT(philosopher_id);
} else {
first_fork = RIGHT(philosopher_id);
second_fork = LEFT(philosopher_id);
}
while (1) {
// Think
printf("Philosopher %d is thinking\n", philosopher_id);
sleep(rand() % 3);
// Acquire forks with deadlock prevention
pthread_mutex_lock(&forks[first_fork]);
printf("Philosopher %d picked up fork %d\n", philosopher_id, first_fork);
pthread_mutex_lock(&forks[second_fork]);
printf("Philosopher %d picked up fork %d\n", philosopher_id, second_fork);
// Eat
printf("Philosopher %d is eating\n", philosopher_id);
sleep(rand() % 3);
// Release forks
pthread_mutex_unlock(&forks[second_fork]);
pthread_mutex_unlock(&forks[first_fork]);
}
return NULL;
}
int main() {
int philosopher_ids[NUM_PHILOSOPHERS];
// Initialize mutexes
for (int i = 0; i < NUM_PHILOSOPHERS; i++) {
pthread_mutex_init(&forks[i], NULL);
philosopher_ids[i] = i;
}
// Create philosopher threads
for (int i = 0; i < NUM_PHILOSOPHERS; i++) {
pthread_create(&philosophers[i], NULL, philosopher_activity, &philosopher_ids[i]);
}
// Wait for threads
for (int i = 0; i < NUM_PHILOSOPHERS; i++) {
pthread_join(philosophers[i], NULL);
}
return 0;
}
Theoretical Foundations of Deadlock Management
The theoretical exploration of deadlocks traces back to fundamental principles of concurrent system design, drawing from mathematical graph theory, resource allocation models, and advanced computational thinking. Understanding these theoretical foundations provides critical insights into how complex systems manage resource interactions.
Graph-based resource modeling represents a pivotal theoretical approach to understanding deadlock dynamics. In this model, computational resources are represented as nodes, with directed edges representing allocation and request relationships. By transforming resource interactions into a mathematical graph, computer scientists can apply sophisticated graph theory algorithms to analyze potential deadlock scenarios.
Formal verification techniques emerge as a sophisticated theoretical method for deadlock prevention. These mathematical approaches involve creating comprehensive computational models that can mathematically prove the absence of deadlock conditions. Researchers use advanced logics and model-checking algorithms to verify that system designs inherently prevent circular resource dependencies.
Advanced Mitigation Techniques
Dynamic resource allocation represents a cutting-edge approach to deadlock mitigation. Rather than relying on static resource assignment strategies, advanced systems implement intelligent, real-time resource management mechanisms that can dynamically adjust resource allocation based on current system conditions.
Predictive resource modeling takes mitigation strategies to a sophisticated level. By implementing machine learning algorithms that analyze historical resource utilization patterns, systems can anticipate potential deadlock scenarios before they occur. These adaptive systems can proactively redistribute resources, adjust thread scheduling, or implement preventive synchronization mechanisms.
Hierarchical resource allocation provides another advanced mitigation strategy. By organizing resources into hierarchical structures with well-defined access protocols, systems can mathematically prevent circular dependency scenarios. This approach implements strict ordering rules that eliminate the possibility of circular wait conditions.
Real-world Deadlock Scenarios
Operating System File System Management demonstrates a classic deadlock-prone environment. Consider a scenario where multiple processes simultaneously attempt to access and modify shared files. One process might hold a read lock on a file while requesting a write lock on another, while a second process holds a write lock and requests a read lock on the first file.
Database Transaction Processing represents another domain exceptionally susceptible to deadlock scenarios. Complex transactional systems involving multiple concurrent database operations can easily create intricate resource dependency chains. A banking system processing simultaneous fund transfers between multiple accounts provides a perfect example of potential deadlock complexity.
Distributed Computing Systems face particularly challenging deadlock scenarios. In a distributed environment spanning multiple networked computers, resource allocation becomes exponentially more complex. Network communication protocols, distributed resource management, and inter-node synchronization create numerous potential deadlock points.
Emerging Research Directions
Quantum Computing Synchronization emerges as a fascinating frontier in deadlock research. Traditional deadlock prevention strategies rely on classical computational models, but quantum computing introduces fundamentally different resource interaction paradigms. Researchers are exploring how quantum entanglement and superposition might provide novel approaches to synchronization challenges.
Artificial Intelligence-driven Deadlock Prevention represents another cutting-edge research domain. Machine learning algorithms can potentially develop adaptive resource allocation strategies that dynamically learn and optimize synchronization mechanisms. These intelligent systems could predict and prevent deadlock scenarios with unprecedented accuracy.
Performance and Optimization Strategies
Performance optimization in deadlock-prevention mechanisms requires a delicate balance between comprehensive prevention and computational efficiency. Each additional synchronization check introduces computational overhead, necessitating intelligent, lightweight prevention strategies.
Adaptive threshold mechanisms provide a sophisticated approach to balancing prevention and performance. Instead of implementing comprehensive checks for every resource request, these systems use probabilistic models and dynamic thresholds to selectively apply more intensive deadlock prevention techniques.
Resource Allocation and Deadlock Prevention Flow
Deadlock Detection Algorithm Flow
Performance Implications
Deadlock prevention and detection mechanisms introduce computational overhead that must be carefully balanced against system performance requirements. Each additional check and validation step consumes processing resources and potentially increases system latency.
Resource management algorithms like the Banker’s Algorithm require complex computational analysis, which can become computationally expensive in systems with numerous threads and resources. The computational complexity grows exponentially with the number of threads and resource types, necessitating intelligent optimization strategies.
Conclusion
Deadlock management represents a sophisticated dance of resource allocation, thread synchronization, and predictive system design. By understanding the fundamental conditions that enable deadlocks and implementing intelligent prevention strategies, developers can create robust, resilient concurrent systems that gracefully handle complex computational scenarios.
The journey through deadlock concepts reveals the intricate challenges of parallel computing. Each prevention strategy represents a nuanced approach to managing the delicate balance between resource utilization and system stability.