Free Space Management
1. Introduction
Free space management is a critical component of file systems that handles tracking, allocation, and deallocation of available storage space. It ensures efficient utilization of storage resources while minimizing fragmentation and maintaining optimal performance.
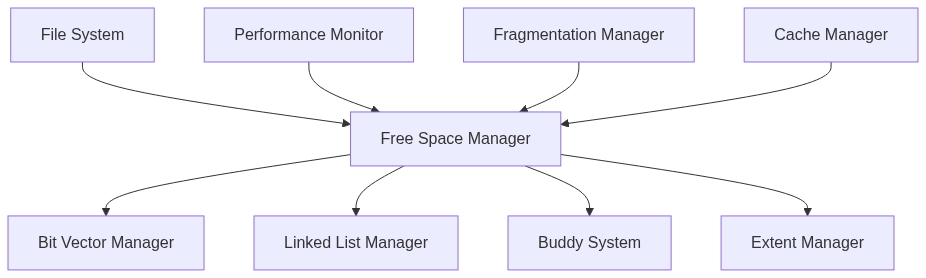
The implementation of free space management directly impacts file system performance, space utilization, and overall system efficiency. Various techniques are employed to manage free space, each with its own trade-offs between complexity, performance, and space overhead.
2. Bit Vector Implementation
Bit vectors (or bitmap) provide a simple and efficient way to track free blocks. Each bit represents a block in the storage system, where 1 typically indicates a used block and 0 indicates a free block.
This method provides quick access to free block status and is particularly efficient for modern systems with sufficient memory to hold the entire bitmap in memory. The implementation below demonstrates a comprehensive bit vector management system.
typedef struct BitVector {
unsigned char *bitmap;
size_t total_blocks;
size_t free_blocks;
pthread_mutex_t lock;
} BitVector;
=BitVector* init_bit_vector(size_t total_blocks) {
BitVector *bv = malloc(sizeof(BitVector));
if (!bv) return NULL;
// Calculate bytes needed (8 bits per byte)
size_t bytes_needed = (total_blocks + 7) / 8;
bv->bitmap = calloc(bytes_needed, sizeof(unsigned char));
if (!bv->bitmap) {
free(bv);
return NULL;
}
bv->total_blocks = total_blocks;
bv->free_blocks = total_blocks;
pthread_mutex_init(&bv->lock, NULL);
return bv;
}
// Set/Clear bit operations
static inline void set_bit(unsigned char *bitmap, size_t bit) {
bitmap[bit / 8] |= (1 << (bit % 8));
}
static inline void clear_bit(unsigned char *bitmap, size_t bit) {
bitmap[bit / 8] &= ~(1 << (bit % 8));
}
static inline int test_bit(unsigned char *bitmap, size_t bit) {
return (bitmap[bit / 8] & (1 << (bit % 8))) != 0;
}
// Allocate a free block
int allocate_block(BitVector *bv) {
pthread_mutex_lock(&bv->lock);
if (bv->free_blocks == 0) {
pthread_mutex_unlock(&bv->lock);
return -1;
}
// Find first free block
for (size_t i = 0; i < bv->total_blocks; i++) {
if (!test_bit(bv->bitmap, i)) {
set_bit(bv->bitmap, i);
bv->free_blocks--;
pthread_mutex_unlock(&bv->lock);
return i;
}
}
pthread_mutex_unlock(&bv->lock);
return -1;
}
// Free a block
int free_block(BitVector *bv, size_t block_num) {
if (block_num >= bv->total_blocks) return -1;
pthread_mutex_lock(&bv->lock);
if (!test_bit(bv->bitmap, block_num)) {
pthread_mutex_unlock(&bv->lock);
return -1; // Block already free
}
clear_bit(bv->bitmap, block_num);
bv->free_blocks++;
pthread_mutex_unlock(&bv->lock);
return 0;
}
3. Linked List Implementation
Linked list implementation maintains a list of free blocks, where each free block contains a pointer to the next free block. This method is memory-efficient but can be slower for large systems due to its sequential nature.
The implementation provides both single and double linked list variants for different use cases and performance requirements.
typedef struct FreeBlock {
int block_number;
struct FreeBlock *next;
struct FreeBlock *prev; // For double-linked list
} FreeBlock;
typedef struct FreeList {
FreeBlock *head;
FreeBlock *tail; // For quick appending
size_t count;
pthread_mutex_t lock;
} FreeList;
// Initialize free list
FreeList* init_free_list() {
FreeList *list = malloc(sizeof(FreeList));
if (!list) return NULL;
list->head = NULL;
list->tail = NULL;
list->count = 0;
pthread_mutex_init(&list->lock, NULL);
return list;
}
// Add blocks to free list
int add_free_blocks(FreeList *list, int start_block, int count) {
pthread_mutex_lock(&list->lock);
for (int i = 0; i < count; i++) {
FreeBlock *block = malloc(sizeof(FreeBlock));
if (!block) {
pthread_mutex_unlock(&list->lock);
return -1;
}
block->block_number = start_block + i;
block->next = NULL;
block->prev = list->tail;
if (list->tail) {
list->tail->next = block;
} else {
list->head = block;
}
list->tail = block;
list->count++;
}
pthread_mutex_unlock(&list->lock);
return 0;
}
// Allocate a block from free list
int allocate_from_list(FreeList *list) {
pthread_mutex_lock(&list->lock);
if (!list->head) {
pthread_mutex_unlock(&list->lock);
return -1;
}
FreeBlock *block = list->head;
int block_num = block->block_number;
list->head = block->next;
if (list->head) {
list->head->prev = NULL;
} else {
list->tail = NULL;
}
free(block);
list->count--;
pthread_mutex_unlock(&list->lock);
return block_num;
}
4. Grouping and Indexing
Grouping and indexing techniques organize free blocks into groups based on size or location, improving allocation efficiency for different request sizes. This approach helps reduce fragmentation and improves allocation performance.
The implementation includes both size-based and location-based grouping strategies.
typedef struct BlockGroup {
int start_block;
int block_count;
struct BlockGroup *next;
} BlockGroup;
typedef struct GroupedFreeSpace {
BlockGroup **size_groups; // Array of groups by size
BlockGroup **zone_groups; // Array of groups by location
int max_group_size;
int zone_count;
pthread_mutex_t lock;
} GroupedFreeSpace;
// Initialize grouped free space manager
GroupedFreeSpace* init_grouped_space(int max_size, int zones) {
GroupedFreeSpace *gfs = malloc(sizeof(GroupedFreeSpace));
if (!gfs) return NULL;
gfs->size_groups = calloc(max_size, sizeof(BlockGroup*));
gfs->zone_groups = calloc(zones, sizeof(BlockGroup*));
if (!gfs->size_groups || !gfs->zone_groups) {
free(gfs->size_groups);
free(gfs->zone_groups);
free(gfs);
return NULL;
}
gfs->max_group_size = max_size;
gfs->zone_count = zones;
pthread_mutex_init(&gfs->lock, NULL);
return gfs;
}
// Add free blocks to appropriate groups
int add_to_groups(GroupedFreeSpace *gfs, int start_block, int count) {
pthread_mutex_lock(&gfs->lock);
// Create new block group
BlockGroup *group = malloc(sizeof(BlockGroup));
if (!group) {
pthread_mutex_unlock(&gfs->lock);
return -1;
}
group->start_block = start_block;
group->block_count = count;
// Add to size-based group
int size_index = count - 1;
if (size_index >= gfs->max_group_size) {
size_index = gfs->max_group_size - 1;
}
group->next = gfs->size_groups[size_index];
gfs->size_groups[size_index] = group;
// Add to zone-based group
int zone = start_block / (gfs->zone_count);
BlockGroup *zone_group = malloc(sizeof(BlockGroup));
if (zone_group) {
*zone_group = *group;
zone_group->next = gfs->zone_groups[zone];
gfs->zone_groups[zone] = zone_group;
}
pthread_mutex_unlock(&gfs->lock);
return 0;
}
// Find and allocate blocks of requested size
int allocate_grouped_blocks(GroupedFreeSpace *gfs, int requested_size) {
pthread_mutex_lock(&gfs->lock);
// Search in size groups
for (int i = requested_size - 1; i < gfs->max_group_size; i++) {
BlockGroup **group_ptr = &gfs->size_groups[i];
while (*group_ptr) {
if ((*group_ptr)->block_count >= requested_size) {
int start_block = (*group_ptr)->start_block;
// Update or remove group
if ((*group_ptr)->block_count == requested_size) {
BlockGroup *to_remove = *group_ptr;
*group_ptr = (*group_ptr)->next;
free(to_remove);
} else {
(*group_ptr)->start_block += requested_size;
(*group_ptr)->block_count -= requested_size;
}
pthread_mutex_unlock(&gfs->lock);
return start_block;
}
group_ptr = &(*group_ptr)->next;
}
}
pthread_mutex_unlock(&gfs->lock);
return -1;
}
5. Buddy System Implementation
The buddy system is an efficient memory allocation scheme that divides memory into blocks of sizes that are powers of two. This method reduces external fragmentation and provides fast allocation and deallocation operations.
When a block is split, it creates two equal-sized “buddy” blocks. During deallocation, if both buddies are free, they can be merged back into a larger block.
typedef struct BuddyBlock {
int start_block;
int size; // Size is always a power of 2
int is_free;
struct BuddyBlock *next;
} BuddyBlock;
typedef struct BuddySystem {
BuddyBlock **free_lists; // Array of free lists for each size
int min_size; // Minimum block size (power of 2)
int max_size; // Maximum block size (power of 2)
int levels; // Number of size levels
pthread_mutex_t lock;
} BuddySystem;
// Initialize buddy system
BuddySystem* init_buddy_system(int min_size, int max_size) {
if (!is_power_of_two(min_size) || !is_power_of_two(max_size) ||
min_size > max_size) {
return NULL;
}
BuddySystem *bs = malloc(sizeof(BuddySystem));
if (!bs) return NULL;
bs->min_size = min_size;
bs->max_size = max_size;
bs->levels = log2(max_size/min_size) + 1;
bs->free_lists = calloc(bs->levels, sizeof(BuddyBlock*));
if (!bs->free_lists) {
free(bs);
return NULL;
}
pthread_mutex_init(&bs->lock, NULL);
// Initialize with one maximum-sized free block
BuddyBlock *initial_block = malloc(sizeof(BuddyBlock));
if (initial_block) {
initial_block->start_block = 0;
initial_block->size = max_size;
initial_block->is_free = 1;
initial_block->next = NULL;
bs->free_lists[bs->levels - 1] = initial_block;
}
return bs;
}
// Find buddy block address
static int find_buddy_address(int block_addr, int block_size) {
return block_addr ^ block_size;
}
// Allocate blocks using buddy system
int buddy_allocate(BuddySystem *bs, int requested_size) {
pthread_mutex_lock(&bs->lock);
// Round up to next power of 2
int size = next_power_of_two(requested_size);
if (size < bs->min_size) size = bs->min_size;
if (size > bs->max_size) {
pthread_mutex_unlock(&bs->lock);
return -1;
}
// Find appropriate level
int level = log2(size/bs->min_size);
// Search for free block, splitting larger blocks if necessary
for (int i = level; i < bs->levels; i++) {
if (bs->free_lists[i]) {
// Found a block to use
BuddyBlock *block = bs->free_lists[i];
bs->free_lists[i] = block->next;
// Split block if necessary
while (i > level) {
i--;
int buddy_addr = find_buddy_address(block->start_block,
block->size/2);
// Create new buddy block
BuddyBlock *buddy = malloc(sizeof(BuddyBlock));
if (buddy) {
buddy->start_block = buddy_addr;
buddy->size = block->size/2;
buddy->is_free = 1;
buddy->next = bs->free_lists[i];
bs->free_lists[i] = buddy;
}
block->size /= 2;
}
block->is_free = 0;
int result = block->start_block;
free(block);
pthread_mutex_unlock(&bs->lock);
return result;
}
}
pthread_mutex_unlock(&bs->lock);
return -1;
}
6. Extent-Based Management
Extent-based management handles free space by tracking contiguous regions of free blocks (extents). This approach is particularly effective for reducing metadata overhead and improving sequential access performance.
typedef struct Extent {
int start_block;
int length;
struct Extent *next;
struct Extent *prev;
} Extent;
typedef struct ExtentManager {
Extent *free_extents;
Extent *used_extents;
int total_blocks;
int min_extent_size;
pthread_mutex_t lock;
} ExtentManager;
// Initialize extent manager
ExtentManager* init_extent_manager(int total_blocks, int min_extent) {
ExtentManager *em = malloc(sizeof(ExtentManager));
if (!em) return NULL;
// Create initial extent covering all blocks
Extent *initial = malloc(sizeof(Extent));
if (!initial) {
free(em);
return NULL;
}
initial->start_block = 0;
initial->length = total_blocks;
initial->next = NULL;
initial->prev = NULL;
em->free_extents = initial;
em->used_extents = NULL;
em->total_blocks = total_blocks;
em->min_extent_size = min_extent;
pthread_mutex_init(&em->lock, NULL);
return em;
}
// Allocate blocks from extent
int allocate_extent(ExtentManager *em, int requested_size) {
pthread_mutex_lock(&em->lock);
Extent *current = em->free_extents;
while (current) {
if (current->length >= requested_size) {
// Found suitable extent
int start_block = current->start_block;
// Create new used extent
Extent *used = malloc(sizeof(Extent));
if (used) {
used->start_block = start_block;
used->length = requested_size;
used->next = em->used_extents;
used->prev = NULL;
if (em->used_extents) {
em->used_extents->prev = used;
}
em->used_extents = used;
}
// Update free extent
if (current->length == requested_size) {
// Remove entire extent
if (current->prev) {
current->prev->next = current->next;
} else {
em->free_extents = current->next;
}
if (current->next) {
current->next->prev = current->prev;
}
free(current);
} else {
// Reduce extent size
current->start_block += requested_size;
current->length -= requested_size;
}
pthread_mutex_unlock(&em->lock);
return start_block;
}
current = current->next;
}
pthread_mutex_unlock(&em->lock);
return -1;
}
7. Cache-Aware Free Space Management
Cache-aware free space management optimizes allocation decisions based on cache behavior and memory access patterns. This implementation considers cache line sizes and memory hierarchies to improve performance.
typedef struct CacheAwareManager {
struct {
void *hot_blocks; // Recently accessed blocks
void *warm_blocks; // Moderately accessed blocks
void *cold_blocks; // Rarely accessed blocks
size_t cache_line_size;
size_t hot_size;
size_t warm_size;
} cache_info;
BitVector *block_status;
pthread_mutex_t lock;
} CacheAwareManager;
// Initialize cache-aware manager
CacheAwareManager* init_cache_aware_manager(size_t total_blocks,
size_t cache_line_size) {
CacheAwareManager *cam = malloc(sizeof(CacheAwareManager));
if (!cam) return NULL;
// Initialize cache structures
cam->cache_info.cache_line_size = cache_line_size;
cam->cache_info.hot_size = cache_line_size * 64; // Example sizes
cam->cache_info.warm_size = cache_line_size * 256;
cam->cache_info.hot_blocks = aligned_alloc(cache_line_size,
cam->cache_info.hot_size);
cam->cache_info.warm_blocks = aligned_alloc(cache_line_size,
cam->cache_info.warm_size);
cam->cache_info.cold_blocks = malloc(total_blocks * sizeof(int));
cam->block_status = init_bit_vector(total_blocks);
pthread_mutex_init(&cam->lock, NULL);
return cam;
}
// Allocate cache-aligned blocks
int allocate_cache_aligned(CacheAwareManager *cam, size_t size) {
pthread_mutex_lock(&cam->lock);
// Round up to cache line size
size_t aligned_size = (size + cam->cache_info.cache_line_size - 1) &
~(cam->cache_info.cache_line_size - 1);
// Try to allocate from hot blocks first
int block = find_free_cached_block(cam->cache_info.hot_blocks,
cam->cache_info.hot_size,
aligned_size);
if (block == -1) {
// Try warm blocks
block = find_free_cached_block(cam->cache_info.warm_blocks,
cam->cache_info.warm_size,
aligned_size);
}
if (block == -1) {
// Fall back to cold blocks
block = find_free_cold_block(cam->cache_info.cold_blocks,
cam->block_status,
aligned_size);
}
pthread_mutex_unlock(&cam->lock);
return block;
}
8. Concurrent Free Space Management
Implementing thread-safe free space management is crucial for modern systems. This section demonstrates lock-free and fine-grained locking approaches to handle concurrent access to free space resources.
typedef struct ConcurrentFreeManager {
struct {
atomic_int *block_status;
atomic_int free_count;
atomic_int total_blocks;
} atomic_data;
struct {
pthread_rwlock_t *segment_locks;
int segment_count;
int blocks_per_segment;
} segments;
} ConcurrentFreeManager;
// Initialize concurrent manager
ConcurrentFreeManager* init_concurrent_manager(int total_blocks, int segment_size) {
ConcurrentFreeManager *cfm = malloc(sizeof(ConcurrentFreeManager));
if (!cfm) return NULL;
// Initialize atomic block status array
cfm->atomic_data.block_status = calloc(total_blocks, sizeof(atomic_int));
atomic_init(&cfm->atomic_data.free_count, total_blocks);
atomic_init(&cfm->atomic_data.total_blocks, total_blocks);
// Initialize segment locks
cfm->segments.segment_count = (total_blocks + segment_size - 1) / segment_size;
cfm->segments.blocks_per_segment = segment_size;
cfm->segments.segment_locks = malloc(cfm->segments.segment_count *
sizeof(pthread_rwlock_t));
if (!cfm->atomic_data.block_status || !cfm->segments.segment_locks) {
free(cfm->atomic_data.block_status);
free(cfm->segments.segment_locks);
free(cfm);
return NULL;
}
// Initialize segment locks
for (int i = 0; i < cfm->segments.segment_count; i++) {
pthread_rwlock_init(&cfm->segments.segment_locks[i], NULL);
}
return cfm;
}
// Lock-free block allocation
int allocate_concurrent_block(ConcurrentFreeManager *cfm) {
int free_blocks = atomic_load(&cfm->atomic_data.free_count);
if (free_blocks <= 0) return -1;
for (int i = 0; i < atomic_load(&cfm->atomic_data.total_blocks); i++) {
int expected = 0;
// Try to atomically set block as used (0 -> 1)
if (atomic_compare_exchange_strong(&cfm->atomic_data.block_status[i],
&expected, 1)) {
atomic_fetch_sub(&cfm->atomic_data.free_count, 1);
return i;
}
}
return -1;
}
// Fine-grained segment locking
int allocate_segment_block(ConcurrentFreeManager *cfm, int preferred_segment) {
if (preferred_segment >= cfm->segments.segment_count) return -1;
// Try preferred segment first
pthread_rwlock_wrlock(&cfm->segments.segment_locks[preferred_segment]);
int block = find_free_block_in_segment(cfm, preferred_segment);
if (block != -1) {
pthread_rwlock_unlock(&cfm->segments.segment_locks[preferred_segment]);
return block;
}
pthread_rwlock_unlock(&cfm->segments.segment_locks[preferred_segment]);
// Try other segments
for (int i = 0; i < cfm->segments.segment_count; i++) {
if (i == preferred_segment) continue;
pthread_rwlock_wrlock(&cfm->segments.segment_locks[i]);
block = find_free_block_in_segment(cfm, i);
if (block != -1) {
pthread_rwlock_unlock(&cfm->segments.segment_locks[i]);
return block;
}
pthread_rwlock_unlock(&cfm->segments.segment_locks[i]);
}
return -1;
}
9. Hierarchical Space Management
Hierarchical space management organizes free space in a tree structure, allowing for efficient searching and allocation of different-sized blocks.
typedef struct SpaceNode {
int start_block;
int size;
int is_free;
struct SpaceNode *left;
struct SpaceNode *right;
struct SpaceNode *parent;
} SpaceNode;
typedef struct HierarchicalManager {
SpaceNode *root;
int min_block_size;
pthread_mutex_t lock;
} HierarchicalManager;
// Initialize hierarchical manager
HierarchicalManager* init_hierarchical_manager(int total_blocks,
int min_block_size) {
HierarchicalManager *hm = malloc(sizeof(HierarchicalManager));
if (!hm) return NULL;
hm->root = malloc(sizeof(SpaceNode));
if (!hm->root) {
free(hm);
return NULL;
}
// Initialize root node with all space
hm->root->start_block = 0;
hm->root->size = total_blocks;
hm->root->is_free = 1;
hm->root->left = NULL;
hm->root->right = NULL;
hm->root->parent = NULL;
hm->min_block_size = min_block_size;
pthread_mutex_init(&hm->lock, NULL);
return hm;
}
// Split node for allocation
static SpaceNode* split_node(SpaceNode *node, int requested_size) {
if (node->size < requested_size * 2) return node;
// Create child nodes
SpaceNode *left = malloc(sizeof(SpaceNode));
SpaceNode *right = malloc(sizeof(SpaceNode));
if (!left || !right) {
free(left);
free(right);
return node;
}
// Initialize left child
left->start_block = node->start_block;
left->size = node->size / 2;
left->is_free = 1;
left->parent = node;
left->left = NULL;
left->right = NULL;
// Initialize right child
right->start_block = node->start_block + node->size / 2;
right->size = node->size / 2;
right->is_free = 1;
right->parent = node;
right->left = NULL;
right->right = NULL;
// Update parent
node->left = left;
node->right = right;
return (requested_size <= left->size) ? left : right;
}
// Allocate blocks hierarchically
int allocate_hierarchical(HierarchicalManager *hm, int size) {
pthread_mutex_lock(&hm->lock);
SpaceNode *current = hm->root;
while (current) {
if (current->is_free && current->size >= size) {
if (current->size >= size * 2) {
current = split_node(current, size);
continue;
}
// Found suitable block
current->is_free = 0;
int result = current->start_block;
pthread_mutex_unlock(&hm->lock);
return result;
}
// Try next node
if (current->left && current->left->is_free) {
current = current->left;
} else if (current->right && current->right->is_free) {
current = current->right;
} else {
// Backtrack
while (current->parent &&
(current == current->parent->right ||
!current->parent->right->is_free)) {
current = current->parent;
}
if (!current->parent) break;
current = current->parent->right;
}
}
pthread_mutex_unlock(&hm->lock);
return -1;
}
10. Fragmentation Management
Fragmentation management involves strategies to prevent, detect, and handle both internal and external fragmentation. This implementation includes defragmentation algorithms and fragmentation metrics.
typedef struct FragmentationManager {
struct {
double external_ratio;
double internal_ratio;
int largest_free_block;
int smallest_free_block;
int free_block_count;
} metrics;
struct {
int *block_sizes;
int *block_addresses;
int count;
} free_blocks;
pthread_mutex_t lock;
} FragmentationManager;
// Initialize fragmentation manager
FragmentationManager* init_fragmentation_manager(int max_blocks) {
FragmentationManager *fm = malloc(sizeof(FragmentationManager));
if (!fm) return NULL;
fm->free_blocks.block_sizes = malloc(max_blocks * sizeof(int));
fm->free_blocks.block_addresses = malloc(max_blocks * sizeof(int));
if (!fm->free_blocks.block_sizes || !fm->free_blocks.block_addresses) {
free(fm->free_blocks.block_sizes);
free(fm->free_blocks.block_addresses);
free(fm);
return NULL;
}
fm->free_blocks.count = 0;
pthread_mutex_init(&fm->lock, NULL);
return fm;
}
// Perform defragmentation
int defragment(FragmentationManager *fm) {
pthread_mutex_lock(&fm->lock);
// Sort free blocks by address
for (int i = 0; i < fm->free_blocks.count - 1; i++) {
for (int j = 0; j < fm->free_blocks.count - i - 1; j++) {
if (fm->free_blocks.block_addresses[j] >
fm->free_blocks.block_addresses[j + 1]) {
// Swap addresses
int temp_addr = fm->free_blocks.block_addresses[j];
fm->free_blocks.block_addresses[j] =
fm->free_blocks.block_addresses[j + 1];
fm->free_blocks.block_addresses[j + 1] = temp_addr;
// Swap sizes
int temp_size = fm->free_blocks.block_sizes[j];
fm->free_blocks.block_sizes[j] =
fm->free_blocks.block_sizes[j + 1];
fm->free_blocks.block_sizes[j + 1] = temp_size;
}
}
}
// Merge adjacent blocks
int write_idx = 0;
for (int read_idx = 1; read_idx < fm->free_blocks.count; read_idx++) {
if (fm->free_blocks.block_addresses[write_idx] +
fm->free_blocks.block_sizes[write_idx] ==
fm->free_blocks.block_addresses[read_idx]) {
// Merge blocks
fm->free_blocks.block_sizes[write_idx] +=
fm->free_blocks.block_sizes[read_idx];
} else {
// Move to next block
write_idx++;
fm->free_blocks.block_addresses[write_idx] =
fm->free_blocks.block_addresses[read_idx];
fm->free_blocks.block_sizes[write_idx] =
fm->free_blocks.block_sizes[read_idx];
}
}
fm->free_blocks.count = write_idx + 1;
pthread_mutex_unlock(&fm->lock);
return fm->free_blocks.count;
}
11. Performance Monitoring
Implementation of performance monitoring systems to track and analyze free space management efficiency.
typedef struct PerformanceMonitor {
struct {
atomic_int allocation_count;
atomic_int deallocation_count;
atomic_int failed_allocations;
atomic_llong total_allocation_time;
atomic_llong total_search_time;
} counters;
struct {
double avg_allocation_time;
double avg_search_time;
double fragmentation_ratio;
double utilization_ratio;
} metrics;
time_t start_time;
pthread_mutex_t lock;
} PerformanceMonitor;
// Record allocation metrics
void record_allocation(PerformanceMonitor *pm,
long long search_time,
long long total_time,
int success) {
atomic_fetch_add(&pm->counters.allocation_count, 1);
atomic_fetch_add(&pm->counters.total_search_time, search_time);
atomic_fetch_add(&pm->counters.total_allocation_time, total_time);
if (!success) {
atomic_fetch_add(&pm->counters.failed_allocations, 1);
}
}
// Generate performance report
void generate_performance_report(PerformanceMonitor *pm) {
pthread_mutex_lock(&pm->lock);
int total_allocs = atomic_load(&pm->counters.allocation_count);
if (total_allocs > 0) {
pm->metrics.avg_allocation_time =
(double)atomic_load(&pm->counters.total_allocation_time) /
total_allocs;
pm->metrics.avg_search_time =
(double)atomic_load(&pm->counters.total_search_time) /
total_allocs;
}
// Generate report
printf("Performance Report:\n");
printf("Total Allocations: %d\n", total_allocs);
printf("Failed Allocations: %d\n",
atomic_load(&pm->counters.failed_allocations));
printf("Average Allocation Time: %.2f ms\n",
pm->metrics.avg_allocation_time);
printf("Average Search Time: %.2f ms\n",
pm->metrics.avg_search_time);
printf("Fragmentation Ratio: %.2f%%\n",
pm->metrics.fragmentation_ratio * 100);
printf("Space Utilization: %.2f%%\n",
pm->metrics.utilization_ratio * 100);
pthread_mutex_unlock(&pm->lock);
}
12. Integration and Best Practices
Here are key guidelines for implementing free space management:
Concurrency Handling
- Use appropriate synchronization mechanisms
- Implement fine-grained locking where possible
- Consider lock-free algorithms for high-performance systems
Performance Optimization
- Maintain balanced data structures
- Implement efficient search algorithms
- Use cache-aware allocation strategies
Fragmentation Management
- Regular defragmentation
- Smart allocation strategies
- Monitor fragmentation metrics
Error Handling
- Implement robust error checking
- Maintain system consistency
- Provide meaningful error messages
13. Future Considerations
Scalability
- Support for larger storage systems
- Distributed free space management
- Cloud storage integration
Optimization
- Machine learning-based allocation
- Predictive defragmentation
- Advanced caching strategies
Integration
- Support for new storage technologies
- Enhanced security features
- Better monitoring and analytics
14. Conclusion
Free space management is crucial for efficient file system operation. Key points:
- Multiple implementation strategies available
- Trade-offs between complexity and performance
- Importance of monitoring and optimization
- Need for concurrent access support
- Regular maintenance and defragmentation
[Next: Day 29 - Advanced File System Topics]