Day 44: Cache Management Internals
Table of Contents
- Introduction to Cache Management
- Cache Coherence Protocols
- Cache Line States and Transitions
- Cache Replacement Policies
- Write-Back and Write-Through
- Cache Prefetching Mechanisms
- Multi-Level Cache Architecture
- Cache Performance Optimization
- Cache Monitoring and Analysis
- Conclusion
1. Introduction to Cache Management
Caches are small, fast memory units that store frequently accessed data, reducing the need to access slower main memory. Effective cache management involves maintaining data consistency, optimizing cache access patterns, and minimizing cache misses.
- Cache Coherence: Ensuring that all caches in a system have consistent views of shared data.
- Cache Line: The smallest unit of data that can be stored in a cache.
- Cache Hit/Miss: A cache hit occurs when the requested data is found in the cache, while a cache miss occurs when the data must be fetched from main memory.
- Cache Policies: Rules that govern how data is stored, replaced, and maintained in the cache.
2. Cache Coherence Protocols
Cache coherence protocols ensure that multiple caches in a system maintain consistent views of shared data. The MESI protocol (Modified, Exclusive, Shared, Invalid) is a widely used cache coherence protocol.
MESI Protocol Implementation
Below is an implementation of the MESI protocol in C:
typedef enum {
MODIFIED,
EXCLUSIVE,
SHARED,
INVALID
} CacheLineState;
typedef struct {
void *data;
uint64_t tag;
CacheLineState state;
bool dirty;
uint32_t access_count;
} CacheLine;
typedef struct {
CacheLine *lines;
size_t num_lines;
size_t line_size;
uint32_t hits;
uint32_t misses;
} Cache;
bool handle_cache_access(Cache *cache, uint64_t address, bool is_write) {
CacheLine *line = find_cache_line(cache, address);
if (line == NULL) {
// Cache miss
line = allocate_cache_line(cache, address);
cache->misses++;
return false;
}
// Cache hit
cache->hits++;
switch (line->state) {
case MODIFIED:
if (!is_write) {
// Read hit on modified line
return true;
}
break;
case EXCLUSIVE:
if (is_write) {
line->state = MODIFIED;
line->dirty = true;
}
break;
case SHARED:
if (is_write) {
invalidate_other_caches(address);
line->state = MODIFIED;
line->dirty = true;
}
break;
case INVALID:
// Should not happen on cache hit
return false;
}
return true;
}
3. Cache Line States and Transitions
Cache line states and transitions are crucial for maintaining cache coherence. Below is an implementation of cache line state management:
typedef struct {
CacheLine *line;
bool success;
CacheLineState new_state;
} StateTransitionResult;
StateTransitionResult transition_cache_line_state(
Cache *cache,
CacheLine *line,
CacheOperation operation
) {
StateTransitionResult result = {
.line = line,
.success = true,
.new_state = line->state
};
switch (operation) {
case CACHE_READ:
switch (line->state) {
case MODIFIED:
case EXCLUSIVE:
// No state change needed
break;
case SHARED:
// No state change needed
break;
case INVALID:
// Need to fetch from memory or other cache
if (fetch_from_memory_or_cache(cache, line)) {
result.new_state = SHARED;
} else {
result.success = false;
}
break;
}
break;
case CACHE_WRITE:
switch (line->state) {
case MODIFIED:
// Already modified, no change needed
break;
case EXCLUSIVE:
result.new_state = MODIFIED;
break;
case SHARED:
if (invalidate_other_copies(cache, line)) {
result.new_state = MODIFIED;
} else {
result.success = false;
}
break;
case INVALID:
if (fetch_exclusive_copy(cache, line)) {
result.new_state = MODIFIED;
} else {
result.success = false;
}
break;
}
break;
}
return result;
}
4. Cache Replacement Policies
Cache replacement policies determine which cache line to evict when the cache is full. Common policies include LRU (Least Recently Used), FIFO (First-In, First-Out), and Random.
Cache Replacement Policy Implementation
Below is an implementation of various cache replacement policies:
typedef enum {
LRU,
FIFO,
RANDOM,
PSEUDO_LRU
} ReplacementPolicy;
typedef struct {
uint64_t access_time;
uint32_t reference_bits;
bool valid;
} ReplacementInfo;
CacheLine* select_replacement_victim(
Cache *cache,
ReplacementPolicy policy
) {
switch (policy) {
case LRU:
return find_lru_victim(cache);
case FIFO:
return find_fifo_victim(cache);
case RANDOM:
return find_random_victim(cache);
case PSEUDO_LRU:
return find_pseudo_lru_victim(cache);
}
return NULL;
}
CacheLine* find_lru_victim(Cache *cache) {
CacheLine *victim = NULL;
uint64_t oldest_access = UINT64_MAX;
for (size_t i = 0; i < cache->num_lines; i++) {
if (cache->lines[i].access_count < oldest_access) {
oldest_access = cache->lines[i].access_count;
victim = &cache->lines[i];
}
}
return victim;
}
5. Write-Back and Write-Through
Write policies determine how data is written to the cache and main memory. Write-Back writes data to the cache first and later to main memory, while Write-Through writes data to both the cache and main memory simultaneously.
Write Policy Implementation
Below is an implementation of write policies:
typedef enum {
WRITE_BACK,
WRITE_THROUGH
} WritePolicy;
typedef struct {
void *data;
size_t size;
uint64_t address;
} WriteBuffer;
bool handle_cache_write(
Cache *cache,
uint64_t address,
void *data,
WritePolicy policy
) {
CacheLine *line = find_cache_line(cache, address);
switch (policy) {
case WRITE_BACK:
if (line != NULL) {
memcpy(line->data, data, cache->line_size);
line->dirty = true;
return true;
}
// Handle write miss
line = allocate_cache_line(cache, address);
if (line != NULL) {
memcpy(line->data, data, cache->line_size);
line->dirty = true;
return true;
}
break;
case WRITE_THROUGH:
// Write to memory immediately
if (!write_to_memory(address, data, cache->line_size)) {
return false;
}
if (line != NULL) {
memcpy(line->data, data, cache->line_size);
line->dirty = false;
}
return true;
}
return false;
}
6. Cache Prefetching Mechanisms
Cache prefetching involves fetching data into the cache before it is needed, reducing cache misses. Common prefetching strategies include sequential, stride, and adaptive prefetching.
Prefetching Implementation
Below is an implementation of cache prefetching:
typedef enum {
SEQUENTIAL,
STRIDE,
ADAPTIVE
} PrefetchStrategy;
typedef struct {
uint64_t last_address;
int stride;
uint32_t confidence;
} PrefetchState;
void prefetch_cache_lines(
Cache *cache,
uint64_t trigger_address,
PrefetchStrategy strategy
) {
static PrefetchState state = {0};
switch (strategy) {
case SEQUENTIAL:
prefetch_sequential(cache, trigger_address);
break;
case STRIDE:
prefetch_stride(cache, trigger_address, &state);
break;
case ADAPTIVE:
prefetch_adaptive(cache, trigger_address, &state);
break;
}
}
void prefetch_sequential(Cache *cache, uint64_t address) {
for (int i = 1; i <= PREFETCH_DEGREE; i++) {
uint64_t prefetch_addr = address + (i * cache->line_size);
if (!is_in_cache(cache, prefetch_addr)) {
initiate_prefetch(cache, prefetch_addr);
}
}
}
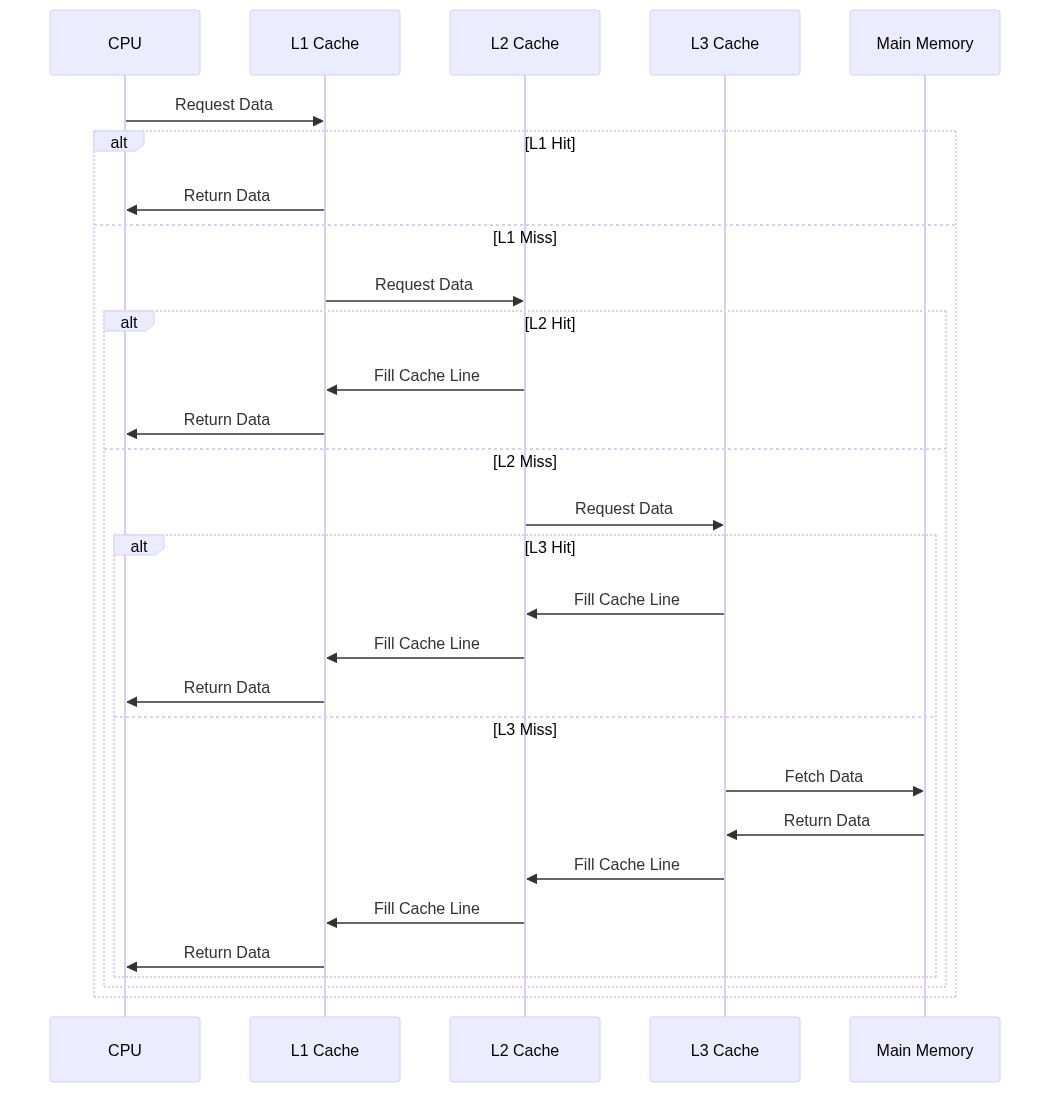
7. Multi-Level Cache Architecture
Modern systems use multiple levels of cache (L1, L2, L3) to balance speed and size. Below is an implementation of a multi-level cache hierarchy:
typedef struct {
Cache *L1;
Cache *L2;
Cache *L3;
uint64_t access_time_L1;
uint64_t access_time_L2;
uint64_t access_time_L3;
} CacheHierarchy;
CacheAccessResult access_cache_hierarchy(
CacheHierarchy *hierarchy,
uint64_t address,
bool is_write
) {
CacheAccessResult result = {
.hit_level = 0,
.access_time = 0
};
// Try L1
if (access_cache(hierarchy->L1, address, is_write)) {
result.hit_level = 1;
result.access_time = hierarchy->access_time_L1;
return result;
}
// Try L2
if (access_cache(hierarchy->L2, address, is_write)) {
result.hit_level = 2;
result.access_time = hierarchy->access_time_L1 +
hierarchy->access_time_L2;
// Fill L1
fill_cache_line(hierarchy->L1, address);
return result;
}
// Try L3
if (access_cache(hierarchy->L3, address, is_write)) {
result.hit_level = 3;
result.access_time = hierarchy->access_time_L1 +
hierarchy->access_time_L2 +
hierarchy->access_time_L3;
// Fill L2 and L1
fill_cache_line(hierarchy->L2, address);
fill_cache_line(hierarchy->L1, address);
return result;
}
// Memory access required
result.hit_level = 0;
result.access_time = calculate_memory_access_time();
return result;
}
Explanation of the above code
- CacheHierarchy Structure: Represents a multi-level cache hierarchy with L1, L2, and L3 caches.
- Cache Access Handling: The
access_cache_hierarchy()function processes cache accesses across multiple cache levels, updating the cache hierarchy as needed.
8. Cache Performance Optimization
Cache performance optimization involves techniques to reduce cache misses and improve access times. We can understand it as below:
9. Cache Monitoring and Analysis
Monitoring tools help analyze cache performance and identify bottlenecks. Below is an implementation of cache monitoring:
typedef struct {
uint64_t total_accesses;
uint64_t hits;
uint64_t misses;
uint64_t evictions;
uint64_t write_backs;
double hit_rate;
double miss_rate;
uint64_t average_access_time;
} CacheStats;
void update_cache_stats(Cache *cache, CacheStats *stats) {
stats->total_accesses++;
if (cache->last_access_hit) {
stats->hits++;
} else {
stats->misses++;
}
if (cache->last_access_eviction) {
stats->evictions++;
if (cache->last_evicted_dirty) {
stats->write_backs++;
}
}
stats->hit_rate = (double)stats->hits / stats->total_accesses;
stats->miss_rate = (double)stats->misses / stats->total_accesses;
stats->average_access_time = calculate_average_access_time(stats);
}
10. Conclusion
Cache management is a critical aspect of modern computer systems, requiring careful consideration of coherence protocols, replacement policies, and optimization techniques. Understanding these concepts is essential for developing high-performance systems.