Day 45: File System Journaling
Table of Contents
- Introduction to File System Journaling
- Journal Structure and Components
- Transaction Management
- Recovery Mechanisms
- Checkpoint Processing
- Write-Ahead Logging
- Journal Space Management
- Conclusion
1. Introduction to File System Journaling
File system journaling is a technique used to ensure data consistency and reliability in file systems. It works by maintaining a log (journal) of changes before they are committed to the main file system. This allows the system to recover quickly from crashes or power failures by replaying or undoing transactions recorded in the journal.
- Transaction Logging: Recording changes to the file system in a log before applying them.
- Atomic Operations: Ensuring that transactions are either fully completed or fully rolled back.
- Crash Recovery: Using the journal to restore the file system to a consistent state after a crash.
- Consistency Guarantees: Ensuring that the file system remains in a valid state at all times.
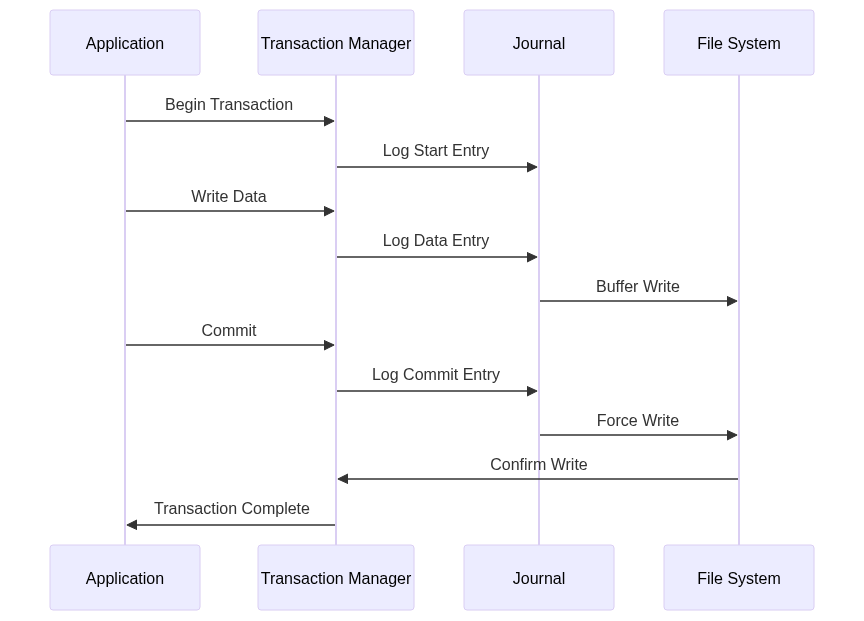
2. Journal Structure and Components
A journal is typically implemented as a circular buffer in a dedicated area of the disk. It consists of a series of journal entries, each representing a change to the file system.
Journal Structure Implementation
Below is an implementation of a basic journal structure in C:
typedef enum {
TXN_START,
TXN_COMMIT,
TXN_ABORT,
DATA_WRITE,
METADATA_UPDATE
} JournalEntryType;
typedef struct {
uint64_t sequence_number;
JournalEntryType type;
uint64_t timestamp;
uint32_t data_length;
void *data;
uint32_t checksum;
} JournalEntry;
typedef struct {
int fd; // Journal file descriptor
uint64_t current_position; // Current write position
uint64_t size; // Total journal size
uint64_t wrap_point; // Position where journal wraps
pthread_mutex_t lock;
bool circular; // Whether journal is circular
} Journal;
Journal* initialize_journal(const char *path, size_t size) {
Journal *journal = malloc(sizeof(Journal));
journal->fd = open(path, O_RDWR | O_CREAT, 0644);
journal->size = size;
journal->current_position = 0;
journal->wrap_point = size;
journal->circular = true;
pthread_mutex_init(&journal->lock, NULL);
// Initialize journal header
JournalHeader header = {
.magic = JOURNAL_MAGIC,
.version = JOURNAL_VERSION,
.creation_time = time(NULL)
};
write(journal->fd, &header, sizeof(header));
fsync(journal->fd);
return journal;
}
3. Transaction Management
Transactions in a journaled file system are sequences of operations that are logged and applied atomically. Below is an implementation of transaction management:
typedef struct {
uint64_t txn_id;
time_t start_time;
List *operations;
JournalEntry *start_entry;
bool committed;
} Transaction;
typedef struct {
Transaction **active_txns;
size_t txn_count;
pthread_mutex_t txn_lock;
Journal *journal;
} TransactionManager;
Transaction* begin_transaction(TransactionManager *tm) {
Transaction *txn = malloc(sizeof(Transaction));
txn->txn_id = generate_txn_id();
txn->start_time = time(NULL);
txn->operations = list_create();
txn->committed = false;
// Create start entry
JournalEntry *start_entry = create_journal_entry(
TXN_START,
txn->txn_id,
NULL,
0
);
pthread_mutex_lock(&tm->journal->lock);
write_journal_entry(tm->journal, start_entry);
pthread_mutex_unlock(&tm->journal->lock);
txn->start_entry = start_entry;
// Add to active transactions
pthread_mutex_lock(&tm->txn_lock);
tm->active_txns[tm->txn_count++] = txn;
pthread_mutex_unlock(&tm->txn_lock);
return txn;
}
bool commit_transaction(TransactionManager *tm, Transaction *txn) {
// Write all pending operations
List *ops = txn->operations;
ListIterator it = list_iterator_create(ops);
pthread_mutex_lock(&tm->journal->lock);
while (list_iterator_has_next(it)) {
JournalEntry *entry = list_iterator_next(it);
if (!write_journal_entry(tm->journal, entry)) {
pthread_mutex_unlock(&tm->journal->lock);
return false;
}
}
// Write commit record
JournalEntry *commit_entry = create_journal_entry(
TXN_COMMIT,
txn->txn_id,
NULL,
0
);
bool success = write_journal_entry(tm->journal, commit_entry);
pthread_mutex_unlock(&tm->journal->lock);
if (success) {
txn->committed = true;
remove_active_transaction(tm, txn);
}
return success;
}
4. Recovery Mechanisms
Recovery mechanisms ensure that the file system can be restored to a consistent state after a crash. Below is an implementation of crash recovery:
typedef struct {
Journal *journal;
List *incomplete_txns;
List *completed_txns;
} RecoveryManager;
bool perform_recovery(RecoveryManager *rm) {
// Scan journal from last checkpoint
uint64_t checkpoint_position = find_last_checkpoint(rm->journal);
set_journal_position(rm->journal, checkpoint_position);
while (has_more_entries(rm->journal)) {
JournalEntry *entry = read_next_entry(rm->journal);
switch (entry->type) {
case TXN_START:
add_incomplete_transaction(rm, entry->txn_id);
break;
case TXN_COMMIT:
move_to_completed(rm, entry->txn_id);
break;
case TXN_ABORT:
remove_incomplete_transaction(rm, entry->txn_id);
break;
case DATA_WRITE:
case METADATA_UPDATE:
if (is_transaction_complete(rm, entry->txn_id)) {
replay_operation(entry);
}
break;
}
}
// Rollback incomplete transactions
return rollback_incomplete_transactions(rm);
}
bool replay_operation(JournalEntry *entry) {
switch (entry->type) {
case DATA_WRITE:
return replay_data_write(entry);
case METADATA_UPDATE:
return replay_metadata_update(entry);
default:
return false;
}
}
5. Checkpoint Processing
Checkpoints are used to reduce the amount of journal data that needs to be scanned during recovery. Below is an implementation of checkpoint processing:
typedef struct {
uint64_t checkpoint_id;
time_t timestamp;
List *active_txns;
uint64_t journal_position;
} Checkpoint;
bool create_checkpoint(Journal *journal, TransactionManager *tm) {
pthread_mutex_lock(&tm->txn_lock);
pthread_mutex_lock(&journal->lock);
Checkpoint *cp = malloc(sizeof(Checkpoint));
cp->checkpoint_id = generate_checkpoint_id();
cp->timestamp = time(NULL);
cp->journal_position = journal->current_position;
// Copy active transactions
cp->active_txns = list_create();
for (size_t i = 0; i < tm->txn_count; i++) {
list_append(cp->active_txns, tm->active_txns[i]);
}
// Write checkpoint record
JournalEntry *cp_entry = create_checkpoint_entry(cp);
bool success = write_journal_entry(journal, cp_entry);
if (success) {
fsync(journal->fd);
update_checkpoint_pointer(journal, cp);
}
pthread_mutex_unlock(&journal->lock);
pthread_mutex_unlock(&tm->txn_lock);
return success;
}
6. Write-Ahead Logging
Write-ahead logging (WAL) ensures that changes are logged before they are applied to the file system. Below is an implementation of WAL:
typedef struct {
void *data;
size_t length;
uint64_t disk_offset;
uint32_t checksum;
} WALRecord;
bool write_ahead_log(Journal *journal, WALRecord *record) {
// Create log entry
JournalEntry *entry = create_journal_entry(
DATA_WRITE,
current_transaction_id(),
record->data,
record->length
);
// Write to journal first
pthread_mutex_lock(&journal->lock);
bool logged = write_journal_entry(journal, entry);
pthread_mutex_unlock(&journal->lock);
if (!logged) {
return false;
}
// Now safe to write to actual location
return write_to_disk(record->disk_offset,
record->data,
record->length);
}
7. Journal Space Management
Journal space management ensures that the journal does not run out of space. Below is an implementation of journal space management:
typedef struct {
uint64_t total_space;
uint64_t used_space;
uint64_t reserved_space;
List *free_segments;
} JournalSpaceManager;
bool allocate_journal_space(JournalSpaceManager *manager,
size_t required_space) {
pthread_mutex_lock(&manager->lock);
if (manager->used_space + required_space >
manager->total_space - manager->reserved_space) {
// Try to reclaim space
if (!reclaim_journal_space(manager, required_space)) {
pthread_mutex_unlock(&manager->lock);
return false;
}
}
manager->used_space += required_space;
pthread_mutex_unlock(&manager->lock);
return true;
}
bool reclaim_journal_space(JournalSpaceManager *manager,
size_t required_space) {
// Find completed transactions that can be truncated
List *completed_txns = find_completed_transactions(manager);
uint64_t reclaimable_space = 0;
ListIterator it = list_iterator_create(completed_txns);
while (list_iterator_has_next(it)) {
Transaction *txn = list_iterator_next(it);
reclaimable_space += calculate_transaction_space(txn);
if (reclaimable_space >= required_space) {
truncate_journal(manager, txn->start_entry->position);
return true;
}
}
return false;
}
8. Conclusion
File system journaling is essential for maintaining data consistency and recovering from system crashes. Understanding the implementation details of journaling mechanisms is crucial for developing reliable file systems.