Leader Election And Its Algorithms
Table of Contents
- Introduction to Leader Election
- Why is Leader Election Important?
- Leader Election in Distributed Systems
- Leader Election in Single-Node Systems
- Leader Election Algorithms
- 5.1 Bully Algorithm
- 5.2 Ring Algorithm
- 5.3 Paxos Algorithm
- 5.4 Raft Algorithm
- 5.5 ZooKeeper’s Leader Election
- Implementation of Leader Election Using Threads in C
- Conclusion
1. Introduction to Leader Election
Leader election is a fundamental problem in computer science, particularly in distributed systems and parallel computing. The goal of leader election is to designate a single node or process as the “leader” that will coordinate actions among a group of nodes or processes. The leader is responsible for making decisions, managing resources, and ensuring consistency across the system.
In a system without a leader, nodes may operate independently, leading to conflicts, inefficiencies, or inconsistencies. By electing a leader, the system can achieve centralized control, simplify decision-making, and ensure orderly execution of tasks.
Leader election is crucial in various applications, including:
- Distributed databases
- Cluster management
- Load balancing
- Consensus protocols
- Fault-tolerant systems
Why is Leader Election Important?
Leader election is a cornerstone of distributed and parallel systems, playing a critical role in ensuring their smooth and efficient operation. In systems where multiple nodes or processes work together, the absence of a leader can lead to chaos, inefficiencies, and inconsistencies. By designating a single node or process as the leader, the system can achieve centralized coordination, fault tolerance, consistency, load balancing, and simplified communication. In this section, we will explore each of these aspects in detail, highlighting why leader election is indispensable in modern computing systems.
2.1 Centralized Coordination
Overview
In a distributed system, multiple nodes or processes work together to achieve a common goal. Without a leader, these nodes may operate independently, leading to conflicts, inefficiencies, and inconsistencies. A leader acts as a central coordinator, making decisions and managing resources for the entire system. This centralized coordination simplifies the design and implementation of distributed algorithms.
Key Benefits
- Decision-Making:
- A leader is responsible for making decisions on behalf of the system. This ensures that decisions are made quickly and consistently, without the need for consensus among all nodes.
- For example, in a distributed database, the leader can decide the order of transactions, ensuring consistency across the system.
- Resource Management:
- The leader manages shared resources, such as memory, storage, and network bandwidth. This prevents resource conflicts and ensures efficient utilization.
- For example, in a cluster management system, the leader can allocate tasks to nodes based on their availability and capacity.
- Simplified Algorithms:
- With a leader, distributed algorithms can be designed to rely on the leader for coordination. This simplifies the algorithms and reduces their complexity.
- For example, in a distributed lock service, the leader can grant or revoke locks, eliminating the need for complex consensus protocols.
Example: Distributed Databases
In a distributed database, the leader coordinates transactions and ensures consistency. Without a leader, nodes may execute transactions independently, leading to inconsistencies and conflicts. The leader ensures that transactions are executed in a consistent order, maintaining the integrity of the database.
2.2 Fault Tolerance
Overview
In a distributed system, nodes may fail or become unresponsive due to hardware faults, software bugs, or network issues. Leader election ensures that a new leader can be chosen to take over in case the current leader fails, maintaining system availability and reliability.
Key Benefits
- High Availability:
- Leader election ensures that the system remains operational even if the current leader fails. A new leader is elected to take over the responsibilities of the failed leader, minimizing downtime.
- For example, in a distributed file system, the leader manages file metadata. If the leader fails, a new leader is elected to ensure that file operations can continue.
- Failure Detection:
- Leader election algorithms include mechanisms for detecting node failures. This ensures that the system can quickly respond to failures and elect a new leader.
- For example, in a cluster management system, the leader periodically sends heartbeat messages to other nodes. If the leader fails to send a heartbeat, a new leader is elected.
- Recovery:
- After a leader fails, the system must recover and resume normal operation. Leader election ensures that a new leader is elected quickly, minimizing the impact of the failure.
- For example, the leader manages message queues in a distributed messaging system. If the leader fails, a new leader is elected to ensure that messages are processed without interruption.
Example: Apache Kafka
Apache Kafka, a distributed messaging system, uses leader election to ensure fault tolerance. Each partition in Kafka has a leader that manages read and write operations. If the leader fails, a new leader is elected to ensure that the partition remains available.
2.3 Consistency
Overview
Consistency is a critical property of distributed systems, ensuring that all nodes have a uniform view of the system state. A leader plays a key role in maintaining consistency by enforcing a consistent order of operations and resolving conflicts.
Key Benefits
- Ordering of Operations:
- The leader ensures that operations are executed in a consistent order across all nodes. This prevents conflicts and ensures that the system state remains consistent.
- For example, in a distributed database, the leader ensures that transactions are executed in a consistent order, maintaining the integrity of the database.
- Conflict Resolution:
- In a distributed system, conflicts may arise when multiple nodes attempt to modify the same data. The leader resolves these conflicts by enforcing a consistent order of operations.
- For example, in a distributed file system, the leader resolves conflicts when multiple nodes attempt to modify the same file.
- State Management:
- The leader manages the system state, ensuring that all nodes have a consistent view of the state. This simplifies the design of distributed algorithms and ensures correctness.
- For example, in a distributed lock service, the leader manages the state of locks, ensuring that all nodes have a consistent view of which locks are held.
Example: Google Spanner
Google Spanner, a globally distributed database, uses leader election to ensure consistency. The leader coordinates transactions and ensures that they are executed in a consistent order across all nodes, maintaining the integrity of the database.
2.4 Load Balancing
Overview
In a distributed system, tasks must be distributed evenly across nodes to prevent bottlenecks and ensure efficient resource utilization. The leader plays a key role in load balancing by allocating tasks to nodes based on their availability and capacity.
Key Benefits
- Task Allocation:
- The leader allocates tasks to nodes based on their availability and capacity. This ensures that tasks are distributed evenly across the system, preventing bottlenecks.
- For example, in a cluster management system, the leader allocates tasks to nodes based on their CPU and memory usage.
- Resource Utilization:
- The leader ensures that resources are utilized efficiently by allocating tasks to nodes that have available capacity. This prevents resource wastage and ensures optimal performance.
- For example, in a distributed computing system, the leader allocates tasks to nodes that have available CPU cycles.
- Scalability:
- Load balancing ensures that the system can scale to handle a large number of tasks. The leader dynamically allocates tasks to nodes, ensuring that the system can handle increasing workloads.
- For example, in a distributed web server, the leader allocates incoming requests to nodes based on their load, ensuring that the system can handle high traffic.
Example: Kubernetes
Kubernetes, a container orchestration system, uses leader election for load balancing. The leader (the Kubernetes scheduler) allocates containers to nodes based on their resource availability, ensuring efficient resource utilization and scalability.
2.5 Simplified Communication
Overview
In a distributed system, nodes must communicate with each other to coordinate their actions. Without a leader, nodes may need to communicate with every other node, leading to high communication overhead. A leader simplifies communication by acting as a central point of contact for all nodes.
Key Benefits
- Reduced Communication Overhead:
- With a leader, nodes only need to communicate with the leader rather than with every other node. This reduces the number of messages exchanged and lowers communication overhead.
- For example, in a distributed lock service, nodes only need to communicate with the leader to acquire or release locks.
- Centralized Coordination:
- The leader acts as a central coordinator, simplifying the communication patterns in the system. Nodes only need to communicate with the leader for coordination, reducing the complexity of distributed algorithms.
- For example, in a distributed database, nodes only need to communicate with the leader to execute transactions.
- Efficient Message Routing:
- The leader can route messages efficiently, ensuring that they reach their intended destination quickly. This reduces latency and improves system performance.
- For example, in a distributed messaging system, the leader routes messages to the appropriate nodes, ensuring that they are delivered quickly.
Example: Apache ZooKeeper
Apache ZooKeeper, a distributed coordination service, uses leader election to simplify communication. The leader acts as a central point of contact for all nodes, reducing communication overhead and ensuring efficient coordination.
Summary of Importance
| Aspect | Description | Key Benefits |
|---|---|---|
| Centralized Coordination | A leader acts as a central coordinator, making decisions and managing resources. | Simplifies decision-making, resource management, and algorithm design. |
| Fault Tolerance | Ensures that a new leader can be chosen if the current leader fails. | Maintains system availability, detects failures, and ensures quick recovery. |
| Consistency | Ensures that all nodes operate consistently. | Enforces consistent order of operations, resolves conflicts, and manages system state. |
| Load Balancing | Distributes tasks evenly across nodes. | Prevents bottlenecks, ensures efficient resource utilization, and supports scalability. |
| Simplified Communication | Reduces communication overhead by centralizing coordination. | Lowers message overhead, simplifies communication patterns, and ensures efficient routing. |
Leader Election in Distributed Systems
Leader election in distributed systems is a fundamental problem that arises in various applications, such as distributed databases, cluster management, and fault-tolerant systems. Unlike single-node systems, where all processes share the same memory space, distributed systems consist of multiple nodes that communicate over a network. This introduces several challenges that make leader election more complex and nuanced.
In this section, we will explore the key challenges of leader election in distributed systems, including asynchronous communication, node failures, network partitions, and scalability. We will also discuss how these challenges influence the design and implementation of leader election algorithms.
3.1 Asynchronous Communication
Overview
In distributed systems, nodes communicate with each other over a network. Unlike in single-node systems, where communication is instantaneous and reliable, network communication in distributed systems is inherently asynchronous. Messages may be delayed, lost, or arrive out of order. This asynchrony introduces uncertainty and makes it difficult to design algorithms that guarantee correctness and liveness.
Challenges
- Message Delays:
- Messages sent between nodes may take an unpredictable amount of time to arrive. This delay can vary depending on network congestion, distance between nodes, and other factors.
- Algorithms must account for these delays to avoid incorrect assumptions about the state of the system.
- Message Loss:
- Messages may be lost due to network failures or congestion. This can lead to incomplete or inconsistent information being available to nodes.
- Algorithms must be robust to message loss and include mechanisms for retransmission or recovery.
- Out-of-Order Messages:
- Messages may arrive in a different order than they were sent. This can cause confusion and lead to incorrect decisions if not handled properly.
- Algorithms must ensure that messages are processed in the correct order or tolerate out-of-order delivery.
Impact on Leader Election
Asynchronous communication complicates the leader election process in several ways:
- Detection of Leader Failure:
- In a synchronous system, a leader’s failure can be detected immediately if it stops sending messages. In an asynchronous system, however, a leader’s failure may be indistinguishable from a message delay or loss.
- Algorithms must use timeouts or other mechanisms to detect leader failure without assuming synchronous communication.
- Election Coordination:
- Coordinating an election among multiple nodes requires exchanging messages to determine the new leader. Asynchronous communication can lead to delays or inconsistencies in this process.
- Algorithms must ensure that all nodes agree on the new leader despite message delays or losses.
Example: Timeout-Based Failure Detection
One common approach to handling asynchronous communication is to use timeouts. Each node periodically sends a heartbeat message to indicate that it is alive. If a node does not receive a heartbeat from the leader within a specified timeout period, it assumes that the leader has failed and initiates an election.
3.2 Node Failures
Overview
In distributed systems, nodes may fail or become unresponsive due to hardware faults, software bugs, or network issues. Node failures can disrupt the leader election process and lead to inconsistencies if not handled properly.
Challenges
- Failure Detection:
- Detecting node failures in a distributed system is challenging because a node’s failure may be indistinguishable from a network partition or message delay.
- Algorithms must use mechanisms such as timeouts or heartbeat messages to detect failures.
- Leader Re-Election:
- When the leader fails, a new leader must be elected to take over its responsibilities. This process must be efficient and ensure that only one leader is elected.
- Algorithms must handle the case where multiple nodes detect the leader’s failure simultaneously and initiate elections.
- Consistency:
- Node failures can lead to inconsistencies in the system if different nodes have different views of the leader or the system state.
- Algorithms must ensure that all nodes agree on the new leader and the system state after a failure.
Impact on Leader Election
Node failures have a significant impact on the leader election process:
- Election Initiation:
- When the leader fails, one or more nodes must detect the failure and initiate an election. This requires a mechanism for failure detection and coordination among nodes.
- Election Contention:
- If multiple nodes detect the leader’s failure simultaneously, they may all initiate elections, leading to contention and potential inconsistencies.
- Algorithms must ensure that only one node becomes the new leader and that all nodes agree on the outcome.
- Recovery:
- After a new leader is elected, the system must recover from the failure and resume normal operation. This may involve re-establishing communication, redistributing tasks, and restoring consistency.
Example: Bully Algorithm
The Bully Algorithm is a classic leader election algorithm that handles node failures by electing the node with the highest ID as the new leader. When a node detects that the leader has failed, it sends an election message to all nodes with higher IDs. If no higher-ID nodes respond, it declares itself the leader.
3.3 Network Partitions
Overview
A network partition occurs when the network splits into multiple disconnected components, preventing nodes in different partitions from communicating with each other. Network partitions can lead to multiple leaders being elected, causing inconsistencies and conflicts in the system.
Challenges
- Split-Brain Problem:
- In the event of a network partition, nodes in different partitions may elect their own leaders, leading to the “split-brain” problem. This can result in conflicting decisions and inconsistencies.
- Algorithms must ensure that only one leader is elected in the entire system, even in the presence of partitions.
- Partition Detection:
- Detecting network partitions is challenging because a partition may be indistinguishable from node failures or message delays.
- Algorithms must use mechanisms such as quorums or majority voting to detect partitions and ensure consistency.
- Partition Recovery:
- When a network partition is resolved, the system must reconcile any inconsistencies that arose during the partition. This may involve merging conflicting states or re-electing a single leader.
- Algorithms must handle partition recovery gracefully to restore consistency and resume normal operation.
Impact on Leader Election
Network partitions complicate the leader election process in several ways:
- Multiple Leaders:
- In the event of a partition, nodes in different partitions may elect their own leaders, leading to multiple leaders and conflicting decisions.
- Algorithms must ensure that only one leader is elected in the entire system, even if partitions occur.
- Quorum Requirements:
- To prevent the split-brain problem, algorithms often require a quorum or majority of nodes to agree on the new leader. This ensures that only one leader is elected even if partitions occur.
- Quorum requirements can increase the complexity and message overhead of the algorithm.
- Partition Recovery:
- When a partition is resolved, the system must reconcile any inconsistencies and re-establish a single leader. This may involve re-electing a leader or merging conflicting states.
- Algorithms must handle partition recovery gracefully to restore consistency and resume normal operation.
Example: Raft Algorithm
The Raft Algorithm is a consensus algorithm that handles network partitions by requiring a majority of nodes to agree on the new leader. If a partition occurs, only the partition with a majority of nodes can elect a leader, preventing the split-brain problem.
3.4 Scalability
Overview
Scalability is a critical consideration in distributed systems, as the number of nodes can range from a few to thousands or more. Leader election algorithms must be efficient and scalable to handle large systems without excessive overhead.
Challenges
- Message Overhead:
- Leader election algorithms often involve exchanging messages among nodes to coordinate the election. In large systems, this can lead to significant message overhead and network congestion.
- Algorithms must minimize message overhead to ensure scalability.
- Coordination Complexity:
- Coordinating an election among a large number of nodes can be complex and time-consuming. Algorithms must ensure that the election process is efficient and does not become a bottleneck.
- Techniques such as hierarchical election or gossip protocols can reduce coordination complexity.
- Failure Handling:
- In large systems, node failures are more likely to occur. Algorithms must handle failures efficiently and ensure that the system can recover quickly.
- Techniques such as failure detection and re-election must be scalable to handle large systems.
Impact on Leader Election
Scalability has a significant impact on the design and implementation of leader election algorithms:
- Message Efficiency:
- Algorithms must minimize the number of messages exchanged during the election process to reduce overhead and ensure scalability.
- Techniques such as gossip protocols or hierarchical election can improve message efficiency.
- Coordination Efficiency:
- Coordinating an election among a large number of nodes can be complex and time-consuming. Algorithms must ensure that the election process is efficient and does not become a bottleneck.
- Techniques such as leader leasing or quorum-based election can reduce coordination complexity.
- Failure Handling:
- In large systems, node failures are more likely to occur. Algorithms must handle failures efficiently and ensure that the system can recover quickly.
- Techniques such as failure detection and re-election must be scalable to handle large systems.
Example: ZooKeeper’s Leader Election
Apache ZooKeeper is a distributed coordination service that provides scalable leader election using a hierarchical structure. Each node creates an ephemeral znode (a temporary node) in ZooKeeper, and the node with the smallest znode path becomes the leader. This approach minimizes message overhead and ensures scalability.
Summary of Challenges
| Challenge | Description | Impact on Leader Election |
|---|---|---|
| Asynchronous Communication | Messages may be delayed, lost, or arrive out of order. | Requires timeout-based failure detection and robust election coordination. |
| Node Failures | Nodes may fail or become unresponsive. | Requires efficient failure detection, leader re-election, and consistency mechanisms. |
| Network Partitions | The network may split into multiple disconnected components. | Requires quorum-based election and partition recovery mechanisms to prevent split-brain. |
| Scalability | The algorithm must work efficiently in systems with a large number of nodes. | Requires minimizing message overhead, reducing coordination complexity, and handling failures efficiently. |
Leader election in distributed systems is a complex problem that requires addressing challenges such as asynchronous communication, node failures, network partitions, and scalability. Each of these challenges influences the design and implementation of leader election algorithms, requiring careful consideration of trade-offs and techniques to ensure correctness, efficiency, and robustness.
By understanding these challenges and the algorithms that address them, developers can design and implement distributed systems that are reliable, scalable, and fault-tolerant. Whether you’re working on a distributed database, cluster management, or fault-tolerant system, leader election plays a pivotal role in ensuring system reliability and performance.
4. Leader Election in Single-Node Systems
In single-node systems (e.g., multi-threaded applications), leader election is simpler because all threads share the same memory space. However, it still requires careful synchronization to avoid race conditions and ensure correctness.
For example, in a multi-threaded application, one thread may act as the leader, while others act as followers. If the leader thread dies or becomes unresponsive, the remaining threads must detect this and elect a new leader.
5. Leader Election Algorithms
Several algorithms have been developed to solve the leader election problem. Each algorithm has its own strengths and weaknesses, making it suitable for different scenarios. Below, we discuss some of the most widely used leader election algorithms.
5.1 Bully Algorithm
Overview
The Bully Algorithm is a classic leader election algorithm designed for distributed systems. It assumes that each node has a unique ID, and the node with the highest ID is elected as the leader.
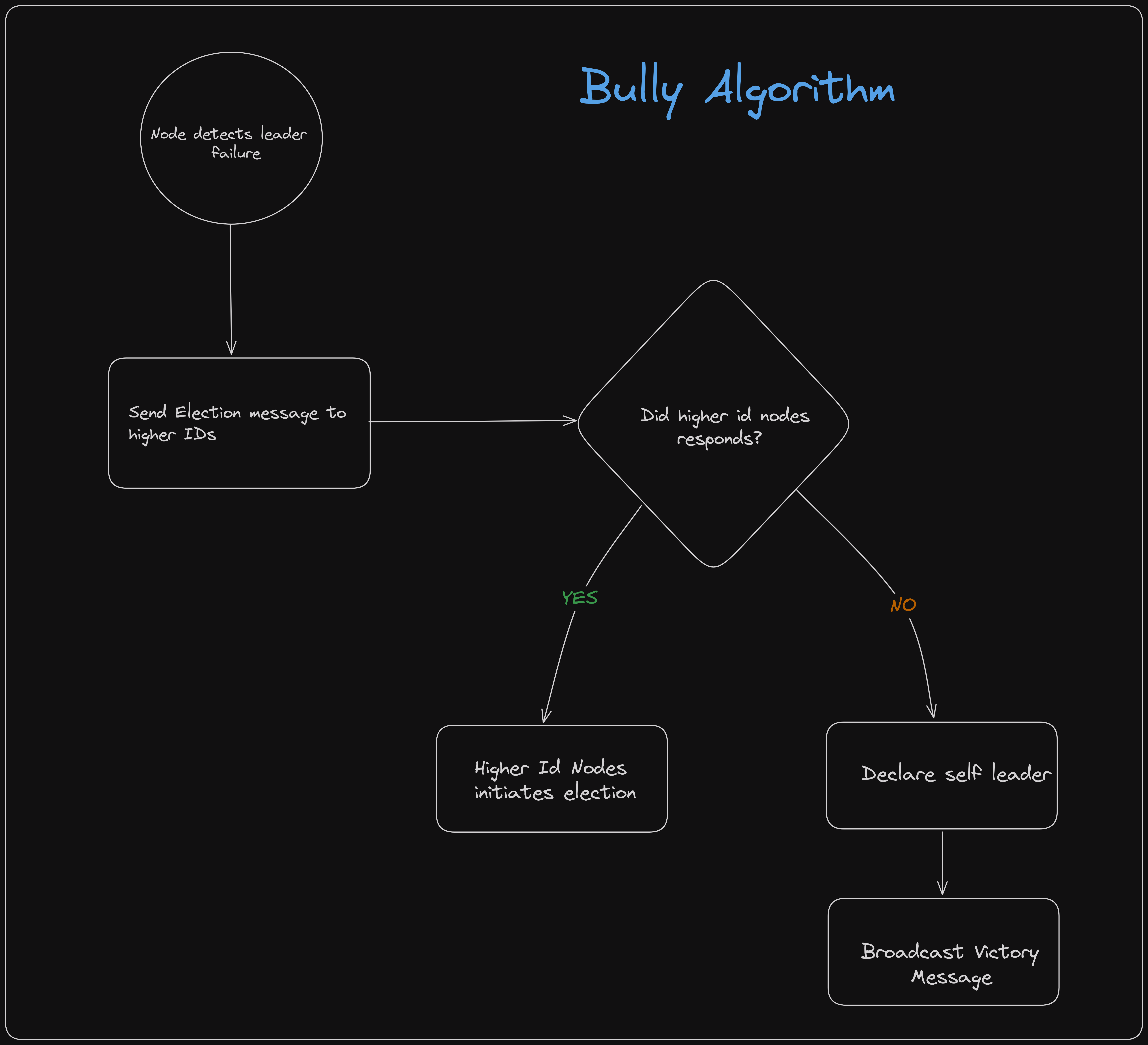
Steps
- Election Initiation:
- When a node detects that the leader has failed, it initiates an election by sending an election message to all nodes with higher IDs.
- Response:
- If a node with a higher ID receives the election message, it responds by sending an “OK” message and initiates its own election.
- Leader Election:
- If the initiating node does not receive any “OK” messages, it declares itself the leader and broadcasts a victory message to all nodes.
- Failure Handling:
- If a node fails during the election process, the algorithm ensures that the node with the next highest ID becomes the leader.
Advantages
- Simple and easy to implement.
- Guarantees that the node with the highest ID becomes the leader.
Disadvantages
- Generates a large number of messages, especially in systems with many nodes.
- Does not handle network partitions well.
5.2 Ring Algorithm
Overview
The Ring Algorithm is another leader election algorithm designed for systems where nodes are arranged in a logical ring. Each node communicates only with its immediate neighbors.
Steps
- Election Initiation:
- When a node detects that the leader has failed, it sends an election message to its neighbor, containing its own ID.
- Message Propagation:
- Each node forwards the election message to its neighbor, adding its own ID if it is higher than the IDs in the message.
- Leader Election:
- When the election message completes a full circle, the node with the highest ID declares itself the leader and broadcasts a victory message.
Advantages
- Generates fewer messages compared to the Bully Algorithm.
- Works well in systems with a logical ring topology.
Disadvantages
- Requires a logical ring structure, which may not be practical in all systems.
- Does not handle node failures during the election process well.
5.3 Paxos Algorithm
Overview
Paxos is a consensus algorithm that can be used for leader election in distributed systems. It ensures that a single leader is elected even in the presence of failures and network partitions.
Steps
- Prepare Phase:
- A node proposes itself as the leader by sending a prepare message to a majority of nodes.
- Promise Phase:
- Nodes respond with a promise message, indicating that they will not accept proposals with lower IDs.
- Accept Phase:
- The proposing node sends an accept message to the majority of nodes, requesting them to accept its proposal.
- Leader Election:
- If a majority of nodes accept the proposal, the proposing node becomes the leader.
Advantages
- Handles failures and network partitions well.
- Ensures that only one leader is elected.
Disadvantages
- Complex to implement and understand.
- Generates a large number of messages.
5.4 Raft Algorithm
Overview
Raft is a consensus algorithm designed to be more understandable than Paxos. It is widely used for leader election in distributed systems.
Steps
- Leader Election:
- Nodes start in the follower state. If a follower does not receive a heartbeat from the leader within a timeout period, it becomes a candidate and initiates an election.
- Voting:
- The candidate requests votes from other nodes. If it receives a majority of votes, it becomes the leader.
- Heartbeat:
- The leader sends periodic heartbeats to the followers to maintain its authority.
Advantages
- Easier to understand and implement than Paxos.
- Handles failures and network partitions well.
Disadvantages
- Requires a majority of nodes to be operational for leader election.
5.5 ZooKeeper’s Leader Election
Overview
Apache ZooKeeper is a distributed coordination service that provides leader election as one of its features. It uses a combination of consensus and atomic operations to elect a leader.
Steps
- ZNode Creation:
- Each node creates an ephemeral znode (a temporary node) in ZooKeeper.
- Leader Election:
- The node with the smallest znode path becomes the leader.
- Failure Handling:
- If the leader fails, its znode is deleted, and the next node with the smallest znode path becomes the leader.
Advantages
- Provides a high-level abstraction for leader election.
- Handles failures and network partitions well.
Disadvantages
- Requires a ZooKeeper ensemble, which adds complexity to the system.
6. Implementation of Leader Election Using Threads in C
To demonstrate leader election in a single-node system, we can implement a simple algorithm using threads in C. In this implementation, one thread acts as the leader, and the others act as followers. If the leader thread dies, the remaining threads detect its absence and elect a new leader.
Code Implementation
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <stdbool.h>
#include <time.h>
#define NUM_THREADS 5
#define HEARTBEAT_INTERVAL 1
#define HEARTBEAT_TIMEOUT 3
pthread_mutex_t lock;
int master_id = -1;
bool master_alive = false;
time_t last_heartbeat_time;
void* master_thread(void* arg) {
int id = *((int*)arg);
printf("Thread %d is now the master.\n", id);
// Master thread sends periodic heartbeats
for (int i = 0; i < 3; i++) { // Simulate master thread stopping after 3 heartbeats
sleep(HEARTBEAT_INTERVAL); // Simulate heartbeat interval
pthread_mutex_lock(&lock);
last_heartbeat_time = time(NULL); // Update last heartbeat time
pthread_mutex_unlock(&lock);
printf("Master thread %d sent a heartbeat.\n", id);
}
// Simulate master thread dying
pthread_mutex_lock(&lock);
master_alive = false;
pthread_mutex_unlock(&lock);
printf("Master thread %d is stopping.\n", id);
return NULL;
}
void* follower_thread(void* arg) {
int id = *((int*)arg);
while (1) {
pthread_mutex_lock(&lock);
time_t current_time = time(NULL);
// Check if the master is alive
if (master_alive && (current_time - last_heartbeat_time > HEARTBEAT_TIMEOUT)) {
printf("Thread %d detected that the master is dead.\n", id);
master_alive = false; // Master is considered dead
}
// If there is no master, elect a new one
if (!master_alive) {
master_id = id;
master_alive = true;
last_heartbeat_time = time(NULL); // Reset heartbeat time
pthread_mutex_unlock(&lock);
printf("Thread %d is promoting itself to master.\n", id);
master_thread(arg); // Promote this thread to master
break;
}
pthread_mutex_unlock(&lock);
// Simulate follower thread doing work
sleep(1);
printf("Follower thread %d is waiting.\n", id);
}
return NULL;
}
int main() {
pthread_t threads[NUM_THREADS];
int thread_ids[NUM_THREADS];
pthread_mutex_init(&lock, NULL);
// Create threads
for (int i = 0; i < NUM_THREADS; i++) {
thread_ids[i] = i;
if (i == 0) {
// First thread is the initial master
master_id = i;
master_alive = true;
last_heartbeat_time = time(NULL); // Initialize heartbeat time
pthread_create(&threads[i], NULL, master_thread, &thread_ids[i]);
} else {
pthread_create(&threads[i], NULL, follower_thread, &thread_ids[i]);
}
}
// Wait for all threads to finish
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
pthread_mutex_destroy(&lock);
return 0;
}
7. Conclusion
Leader election is a critical problem in distributed and parallel systems, ensuring centralized coordination, fault tolerance, and consistency. Various algorithms, such as the Bully Algorithm, Ring Algorithm, Paxos, Raft, and ZooKeeper’s leader election, provide solutions tailored to different system requirements.
In single-node systems, leader election can be implemented using threads and synchronization mechanisms, as demonstrated in the C code above. This implementation simulates a leader thread that periodically sends heartbeats and stops after a certain period, allowing follower threads to detect its absence and elect a new leader.
Understanding leader election algorithms and their implementations is essential for designing robust and efficient distributed systems. Whether you’re working on a distributed database, cluster management, or fault-tolerant systems, leader election plays a pivotal role in ensuring system reliability and performance.
This blog post provides a comprehensive overview of leader election, its importance, and its algorithms, along with a practical implementation in C. It is designed to be both informative and accessible, making it a valuable resource for readers interested in distributed systems and parallel computing.