Apache Kafka: A Deep Technical Dive Into Distributed Messaging
Introduction
Apache Kafka stands as one of the most robust distributed messaging systems in modern software architecture. Originally developed by LinkedIn in 2011, it has evolved into a cornerstone technology for handling real-time data feeds and event streaming at massive scale. This comprehensive analysis delves into the technical intricacies of Kafka, exploring its architecture, implementation details, and the engineering decisions that make it exceptionally scalable and reliable.
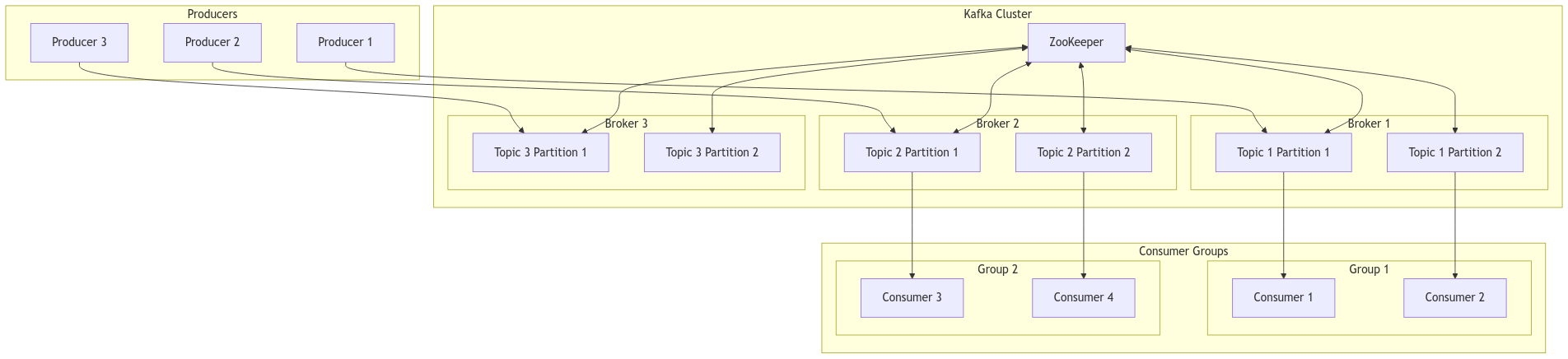
Core Architecture and Components
Message Brokers and Distribution
At its heart, Kafka operates as a distributed messaging system built around the concept of brokers. These brokers serve as the fundamental building blocks that enable Kafka’s impressive scalability. A broker is essentially a server instance that handles message storage and distribution, but its implementation goes far beyond simple message queuing.
Each broker maintains multiple partitions, which are the basic units of parallelism in Kafka. Partitions represent ordered, immutable sequences of messages, implementing a commit log pattern. This design choice is crucial because it enables Kafka to handle massive throughput while maintaining message ordering guarantees within partitions.
The broker implementation includes sophisticated mechanisms for handling message persistence. Messages are written to disk in a highly optimized manner, utilizing the operating system’s page cache and sequential I/O patterns. This approach allows Kafka to achieve remarkable throughput without sacrificing durability.
Topics and Partitioning Strategy
Topics in Kafka represent logical categories of messages, but their implementation involves complex partitioning strategies. When a topic is created, it’s divided into multiple partitions that can be distributed across different brokers. This partitioning mechanism is fundamental to Kafka’s scalability model.
The partitioning strategy involves several key technical considerations:
- Partition Assignment: Messages are assigned to partitions based on a partitioning key, using consistent hashing to ensure even distribution.
- Replication Factor: Each partition maintains multiple replicas for fault tolerance, with one replica designated as the leader.
- Partition Leadership: The leader handles all read and write operations for the partition, while followers maintain synchronized copies.
Understanding these aspects is crucial because they directly impact system performance and reliability. Proper partition configuration can mean the difference between a system that scales gracefully and one that becomes a bottleneck.
Producer Architecture and Implementation
Message Production Pipeline
Producers in Kafka implement a sophisticated pipeline for message delivery. The process begins with message creation and moves through several stages before reaching the broker. Let’s examine the technical details of this pipeline:
- Message Batching: Producers implement smart batching algorithms that aggregate messages bound for the same partition. This batching mechanism includes configurable parameters:
- batch.size: Maximum size of a message batch in bytes
- linger.ms: Maximum time to wait for batch completion
- Compression: Messages can be compressed at the producer level using various algorithms (gzip, snappy, lz4, zstd). The compression occurs at the batch level, making it highly efficient for larger batches.
Producer Guarantees and Acknowledgments
Producers implement different levels of delivery guarantees through acknowledgment mechanisms:
// Example producer configuration for different guarantee levels
Properties props = new Properties();
// acks=0: Fire and forget
props.put("acks", "0");
// acks=1: Leader acknowledgment
props.put("acks", "1");
// acks=all: Full replica acknowledgment
props.put("acks", "all");
These acknowledgment levels represent different trade-offs between performance and reliability. The implementation includes sophisticated retry mechanisms and failure handling:
- Retry Logic: Producers implement exponential backoff for retries
- Idempotency: Optional idempotent producer feature prevents duplicate messages
- Transaction Support: Atomic multi-partition writes
Consumer Architecture and Implementation
Consumer Groups and Partition Assignment
Consumer groups represent one of Kafka’s most powerful features for scalable message processing. The implementation involves complex coordination between consumers within a group:
- Group Coordination Protocol:
- Consumer group leader election
- Partition assignment strategies
- Rebalancing protocols
- Offset Management:
- Committed offset tracking
- Consumer position management
- Offset reset strategies
The technical implementation ensures that each partition is consumed by exactly one consumer within a group, enabling parallel processing while maintaining ordering guarantees.
Consumer Performance Optimization
Consumers implement several optimization techniques to achieve high throughput:
- Fetch Size Management:
// Example consumer configuration for fetch size Properties consumerProps = new Properties(); consumerProps.put("fetch.min.bytes", "1024"); consumerProps.put("fetch.max.bytes", "52428800"); consumerProps.put("max.partition.fetch.bytes", "1048576"); - Prefetching Mechanism: Consumers implement a sophisticated prefetching mechanism that maintains a buffer of fetched messages while processing the current batch. This reduces the likelihood of pipeline stalls.
Replication and Fault Tolerance
Leader Election and Consensus
Kafka’s replication mechanism relies on a sophisticated leader election protocol implemented using ZooKeeper. The technical details of this implementation include:
- ISR (In-Sync Replicas) Management:
- Replica lag monitoring
- ISR set maintenance
- Leader eligibility criteria
- Leader Election Process:
- Controller election
- Partition leadership assignment
- State change propagation
Data Consistency and Replication Protocol
The replication protocol implements several key features to ensure data consistency:
- High Watermark Tracking:
- Offset tracking across replicas
- Consistency guarantee management
- Consumer visibility control
- Replica Synchronization:
- Fetch requests from followers
- Log truncation handling
- Replica catch-up mechanisms
Performance Optimizations
Zero-Copy Implementation
One of Kafka’s most significant performance optimizations is the zero-copy mechanism for transferring data. This implementation bypasses traditional copying through user space:
// Simplified pseudocode demonstrating zero-copy concept
public class ZeroCopyExample {
public void transferMessage(FileChannel source, SocketChannel destination) {
// Direct transfer from file to socket
source.transferTo(position, count, destination);
}
}
The actual implementation leverages operating system capabilities for direct memory-to-socket transfer, significantly reducing CPU overhead and memory usage.
Batch Processing and Compression
Batch processing in Kafka involves several optimization techniques:
- Batch Aggregation:
- Dynamic batch size adjustment
- Timeout-based batch completion
- Compression ratio optimization
- Memory Management:
- Buffer pooling
- Memory pressure handling
- Garbage collection optimization
Monitoring and Metrics
Key Performance Indicators
Kafka implements a comprehensive metrics system that tracks various aspects of system performance:
- Broker Metrics:
- Message rates
- Partition leadership distribution
- Resource utilization
- Producer/Consumer Metrics:
- Throughput rates
- Latency measurements
- Error rates
Implementation of Monitoring
The monitoring implementation includes:
- JMX Integration:
// Example metric implementation public class KafkaMetrics { private final Meter messageRate; private final Histogram batchSize; public void recordBatch(int size) { messageRate.mark(); batchSize.update(size); } } - Custom Metric Collectors:
- Performance counters
- Health check implementations
- Alert threshold management
Security Implementation
Authentication and Authorization
Kafka implements several security mechanisms:
- SASL Implementation:
- Multiple mechanism support (PLAIN, SCRAM, GSSAPI)
- Credential management
- Authentication workflow
- ACL Management:
- Permission models
- Resource patterns
- Authorization cache
Encryption and SSL/TLS
The security implementation includes:
- SSL/TLS Configuration:
// Example SSL configuration Properties props = new Properties(); props.put("security.protocol", "SSL"); props.put("ssl.truststore.location", "/path/to/truststore"); props.put("ssl.keystore.location", "/path/to/keystore"); - Certificate Management:
- Trust store handling
- Key rotation
- Certificate validation
Stream Processing
Kafka Streams API
Kafka Streams implements a powerful processing framework:
- Topology Building:
// Example Streams topology StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("input-topic"); KStream<String, String> processed = source .filter((key, value) -> value != null) .map((key, value) -> KeyValue.pair(key, value.toUpperCase())); - State Management:
- Local state stores
- Changelog topics
- State restoration
Processing Guarantees
The streams implementation provides:
- Processing Semantics:
- Exactly-once processing
- Transaction coordination
- State store consistency
- Fault Tolerance:
- Task assignment
- State recovery
- Rebalancing protocols
Conclusion
Apache Kafka represents a sophisticated implementation of distributed messaging that has revolutionized how we handle real-time data streams. Its architecture combines careful engineering decisions with powerful optimizations to achieve remarkable scalability and reliability. Understanding these technical details is crucial for anyone working with large-scale distributed systems.
The system’s success lies in its careful balance of consistency guarantees, performance optimizations, and operational simplicity. As data processing needs continue to grow, Kafka’s robust architecture provides a solid foundation for building scalable, real-time data pipelines.